
AIでドットを作成するとしましょう。
- 完全なドットの作成は可
- キャラクターの差分作成は可
- 簡単なアニメも可
- カラーパレット、色数の固定が難関
これがぼくのAIドット絵作成、ピクセルアートDIYの答えです。で、当面の課題が色味と色数です。
その他の諸々は2025年末から2026年初頭のツールやモデルの爆発的進化でほぼクリアされました。



ぼくは画像編集できますが、絵を描けません。しかし、あれやこれやを駆使すれば、このような素材をさくっと作成できます。
また、冬の自転車オフシーズンの合間に暇を持て余して、自作PCにAI環境をてんこもりに構築したので、ドット絵に限らず、多彩なスタイルの画像や動画を自由に作れます。
と、あれやこれやをやれますが、リッチなイマドキの表現を脇に置いて、ファミコン世代のど真ん中の思い入れから『ドット絵』の作成に惹かれます。
で、ここ一月ほどの試行錯誤の結論が『カラーがボス』です。色味と色数がなかなかの強敵だ。
この記事ではドット絵作成のツールやワークフローを紹介します。
ドット絵って?
ドット絵は点(ドット)の絵ですから、広義には点描の一種です。スーラやシニャックが有名です。
また、モニター画面のドットは四角形ですから、モザイク画やタイル画の親戚筋でもあります。ポンペイの遺跡のやつが有名です。
何よりドット絵はぼくらの世代では『ゲームの描画方法』を直接的に意味します。ファミコン、スーファミ世代には超おなじみです。
こういうやつです。

これを『ドット絵』と呼ぶか、『ピクセルアート』と言うかでおおよその年代や系譜が分かります。Nvidiaのチップをなんて呼ぶ? グラボ、ビデオカード、GPU? と同じく。
ちなみにドット絵風のカクカクの絵はpixel artで、マインクラフトやレゴみたいなカクカクの疑似3D絵はvoxel artです。
AIが作れるのはドット絵風の画像
ドット絵、点描、モザイク画、タイル画は伝統的な手法です。とくに生成AIはゲーム文化の眷属みたいなものです。モデルはこのスタイルを学習して、理解します。
GPTやGeminiのチャットに”ramen,pixel art”などのプロンプトを打てば、高品質なドット絵風の一丁を頂けます。

ラーメンにしいたけ? 和風創作系ですか? うーん、今日のぼくの口はこってりだけどなー。
ところで、このしいたけラーメンは完全なドット絵ではありません。旧SNKやカプコン、スクエア、エニックス、アトラスの師匠の前では確実に不合格です。
理由はカクカクの精度です。上のラーメンのネギorニラを拡大しましょう。

10倍あたりで四角形のエッジがぼやけ、ドットの不揃いと色のにじみが露になります。これはドット絵の定義から外れます。
つまり、AIが作れるのは完全な真ドット絵でなく、ドット絵『風』の画像です。牛乳でなく加工乳製品、カニでなくカニカマのごとく。
ドット絵、ピクセルアートの定義
狭義の完全ドット絵、ピクセルアートの定義は以下のようなものです。
- ニアレストでぼやけない
- ソリッドカラー
- パレット固定
源流はデジタルゲームの描写方法です。当時のファミコンの性能では1キャラは3色+透明の4色でした。おかげでマリオの目の色は白青黒でなく単色の芥子色です。
ここからデジタルグラフィックがリッチになり、8bitや16bitを経て、約1,677万色フルカラーに至りました。
画像生成AIは最近の子ですから、余裕でこのフルカラーを使います。というか、このフルカラーでしか描けません。
生成モデルは「4色で書いて」と指示を受けても、4色ベースのグラデーションをガンガン使って、100色ぐらいで4色風に見せます。
上のラーメンのネギも20色くらいのリッチな表現です。遠目には分かりませんが、近影では分かります。これがぼやけやにじみになる。
もっとも、ぱっと見はドット絵です。そう見える。一枚絵として成立する。なんでゲーマーの価値観では不合格になるか? え、古株のマウントですか?
でも、『本場の味 博多とんこつラーメン!』の店で創作系和風あっさりラーメンが出てきたら、文句の一つも出ません?
ぼくは牛乳をこよなく愛飲しますが、偽ミルク、牛乳もどきの類を受け付けません。クリープも微妙。やはり、通が求めるのは本物です。
かつて夏休み前のテスト期間中に勉強をほっぽり出して旧SNS本社前のNEOGEOランドへせっせとKOFのロケテストしに通ったこの口にはドット絵『風』の画像は薄味です。

1995~1997年あたりの全世界のゲーム文化の重力の中心は江坂にあったというのがぼくの持論です。まあ、江坂の象徴だったSNKも二駅先の新大阪に移転しましたが・・・
偽ドット絵の弱点
偽ドット絵の弱点は真ドット絵の裏返しです。
- ぼやける
- にじむ
- カラー数
最近の大作ゲームはフルカラー、フルボイスです。ドット絵はAAA級タイトルでは過去の産物だ。
しかし、小規模開発やインディーズ、フリーゲームではドット絵はまだまだ現役です。フルCGや手書きアニメ、リアルタイムレイトレーシングは個人や零細には圧倒的に重荷だ。
ことさらにカラー数、パレットの色指定はアニメやゲームでは重要です。
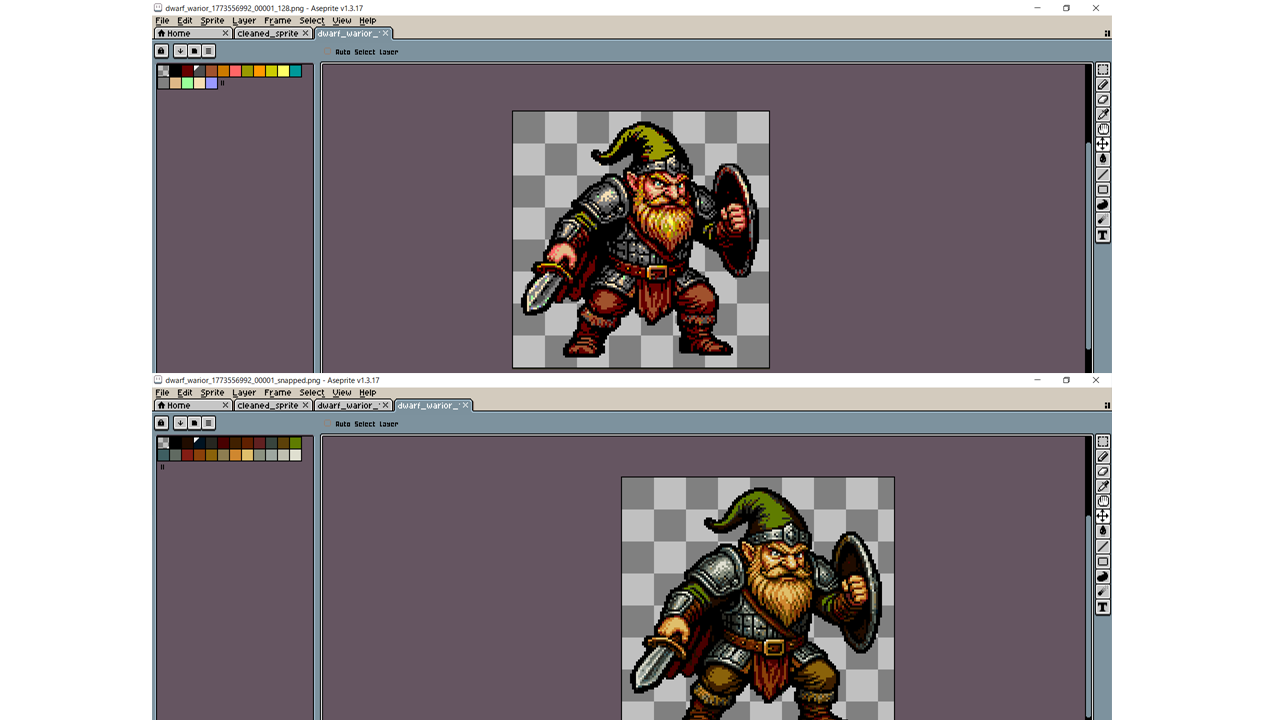
下の絵はドット絵風の生成画像の編集画面です。赤い点は1ドット、左枠はカラーパレットですが、緑のバリエーションはこんなに要らない。
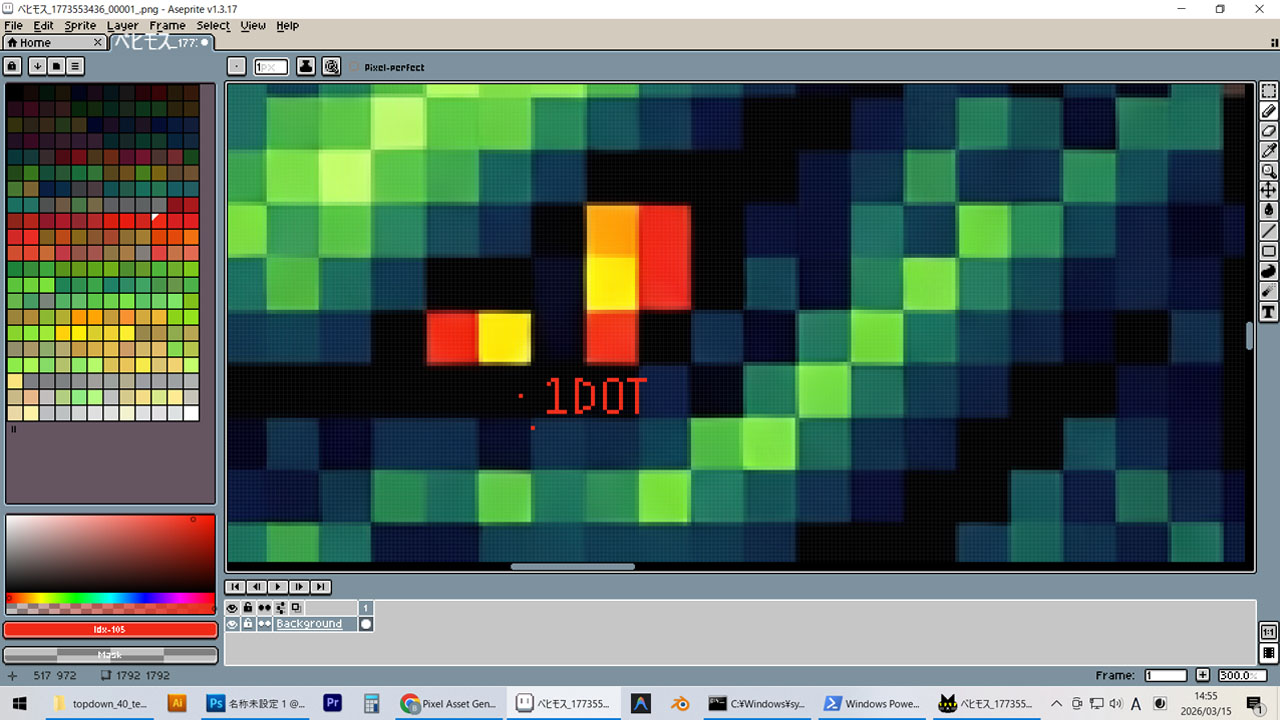
もっとも、これは下書きです。これをベースにして、ドット絵を作ります。ツールでサイズ縮小、減色、背景透過して、有料ソフトのPhotoshopやAsepriteで仕上げます。
こちらはafterです。カラーはここまで減りました。23+1透過の24です。
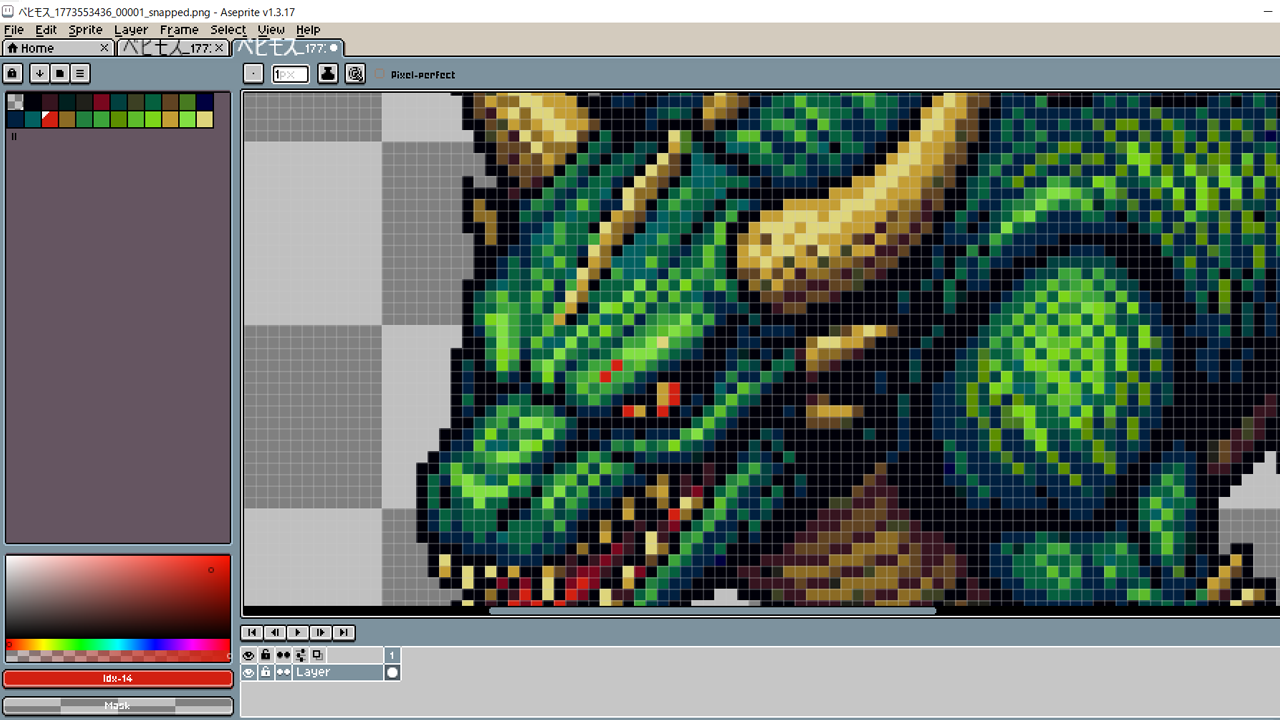
まだ、緑がダブつきますが、多分にこちらはうるさい古参ゲーマーやドット絵マイスターのお墨付きを貰えます。実際、出来栄えは即戦力レベルです。
理想はベースカラー、明るい面の少し薄いカラー、暗い面の少し濃いカラーの3色です。
カラーを少なく絞ると、簡単に色違いのキャラを作れます。これは旧エニックスのお家芸です。青いのはスライム、赤いのはスライムベスです。
ただし、これはまれに悲劇を起こします。
初代ドラクエIIIで勇者の父親オルテガはカンダタやさつじんきの色違いで、上半身裸、覆面、マント、半パン、手斧の変態外見でした。パパスの最期に隠れますが、地味に悲劇です。
それから、Vのパパスの孫=主人公の倅と娘ですが、この二人の髪の色はビアンカ(黄)、フローラ(青)で変わります。ザ・色違いの妙です。
ちなみにオルテガの独自グラフィックはSFCリメイク版のフィールドキャラを経て、2025年リメイク版でコンセプトアート付きの鳥山絵になりました。悲劇からざっと30年です。
もっとも、リメイク版オルテガはバキバキのドット絵でなく、はやりのレトロリッチなHD描写です。この技法はスクエニリメイク班の十八番です。
AIドット絵の作り方 下準備
AIでドット絵『風』の画像を作るのは簡単です。”pixel art”のじゅもんでスタイルやタッチがそうなります。
ただし、上述のようにこれは完全なドット絵ではありません。この伝統的グラフィックスタイルと画像生成の描写方法は基本的に相反します。
そして、
- 色固定
- 背景の透かし
現時点ではこの二つが不可です。画像生成AIは透過色を扱えない。背景の切り抜きは古典的プログラムや人間の仕事です。
必要なツール
ここからぼくの実際の手順やツールを紹介します。
PCの構成です。
- GPU RTX3090 VRAM 24GB
- CPU RYZEN 9 5950X
- RAM 32GB
- ストレージ6TB
YouTube動画編集用兼ゲーム用機体にビットコインマイニングの遺産RTX3090を搭載したマシーンです。

RTX 3090のVRAM 24GBには20GBクラスのAIモデルを乗せられますから、各種の軽量モデルの最上位版をおおよそ快適に動かせます。しかし、メモリが少し足りません。
ライブラリやソフトです。
- Python
- Git
- CUDA
- Comfyui
この4つは必須です。
次がオプションです。
- Rust ※Pixel Snapper用言語
- Google Antigravity ※自作ツール作成用アプリ
Pixel Snapperは2025年12月に出た話題の完全ドット絵変換ツールです。Web版は無料のサービスで、コードはオープンソースです。
Antigravityは2025年11月に出たGoogleのエージェントツールです。GeminiやClaudeと連携して、ローカル環境の構築や自作ツールの作成に活躍します。
たとえば、このAntigravityを自分のPCに置いて、「Pythonの環境を構築して、Pixel Snapperを入れて」と言えば、数分で必要な言語やライブラリを揃えられます。
あとは編集ソフトです。
- Photoshop
- Aseprite
Photoshopは大昔の買取版のマスターコレクションですが、ぼくの使い方=ブログの画像やYoutubeのサムネとかでは現役です。
Asepriteはドット絵編集用の最強ソフトです。1000円くらい。ぼくはSteamのセールで買いました。
で、編集ソフト以外はオープンorフリーです。一応、Antigravityもまだ無料(パイロット版?)です。AIプランを登録しないと、すぐにクレジット制限を食らいますけど。
正直、この環境は趣味のドット絵作りにはオーバースペックです。しかし、道楽とはそういうものです。
画像生成モデル
次は画像生成モデルです。かつての王者だったStable Diffusionはすっかりオワコン化して、新興勢力がいろいろ現れました。
単純な描写性能の最強はおそらくGoogleのNano Banana 2です。しかし、こいつの無料枠はせいぜい5枚くらいです。5枚では当たりは出ないし、差分は揃わない。
最近の無料モデルの候補は
- Flux
- Zimage
- Qwen Image
のどれかです。
FluxはBlack ForestLabsのモデルで、Stable Diffusionの実質的な後継です。SDの開発者が関わります。
QwenはAlibabaのオープンソースです。Alibabaはこのブログでは海外通販のAliExpressでもうおなじみです。縁があるね。
ZimageもAlibabaの軽量高速モデルです。より家庭用向けで、16GBくらいのVRAMでサクサク動きます。
ぼくはFluxをしばらく使って、バリエーションの多さと日本語含むアジア圏の言語能力の理解の良さに惹かれて、Qwen系に鞍替えし、二種のバージョンを使い分けます。
- Qwen 2512 steps4 ※主にベース作成
- Qwen 2511 Edit steps4 ※部分書き換えやポーズ変更
どちらもカスタムモデルですが、特性がすこし違います。ちなみに4つの番号は発表年月を表します。2512→2025年12月版。現状、2603や2604の情報はまだ出ません。
このQwenの二つのバージョンに同じCFG、Steps、Seedで”pixel art”,”ベヒモス”を投げました。


2511はよりレトロなFC時代のドット絵、ピクトグラムっぽくなります。2512はバッキバキのゴリゴリドット絵です。
この差は偶然ではありません。100枚ほどの実験でこの傾向が共通します。

2511 Edit版は2025年後半にSNSで流行ったピクセルアートスタンプぽいスタイルをはっきり出します。”pixel art”のプロンプトがloraのトリガーみたいにはっきり掛かる。もしや、lora込み?
このようにバージョンが変われば、結果がガラッと変わります。
で、ぼくは旧SNKのメタルスラッグ的なゴリゴリドットの信者ですから、基本的に2512で生成します。以下のサンプルも2512の産物です。
しかし、2512は書き換えには不向きです。Edit版でないからか? 正式ファイル名は
qwen_image_2512_fp8_e4m3fn_scaled_comfyui_4steps_v1.0.safetensors
です。ベース版でなく、19GB版の方です。高速版のloraが含まれますから、lightning steps 4のloraなしでさくさく生成が進みます。
さらに一枚絵のモーションの差分を出すときには動画生成モデルを併用します。
- Wan2.2
- Hunyuan Video 1.5
WanはQwenと同じくAlibabaのオープンソースです。しかし、ぼくのやり方ではうまく動きません。良い動きを出せない。
HunyuanはTencentのモデルです。ぼくはドット絵のアニメの作成にはこちらを使います。
はたまた、動作のコマ送りのストップモーションの全部を一枚のキャンバスで一気に書くか。
しかし、それぞれの難所があります。
- 複数ストップモーションを一気に描く→細部が崩れる
- 動画→生成時間が伸びる
- 精細な絵をposeやキャニーで複数回に分けて作る→色が変わる
ぼくは一貫性を重視して、2の手法を主に使います。で、不足分のフレームを3で作って、カラーを手動で合わせる。
上のドワーフさんの歩行モーションは動画でほぼそろいました。ここからツールで全フレーム(4F飛ばしくらいで)を切り出して、いいとこだけを抽出します。
歩行の最小ロットはだいたい8枚くらいです、右足4F、左足4Fみたいに。
ぱっと見には全部が同じキャラに見えますが、1フレームごとに目の色が変わるとか、ボタンみたいな小物が消失するとかは日常茶飯事です。
でかいリッチな絵の1ドットの変化は微細ですが、小さなピクセルアートのそれは甚大です。もとの目が1ドット→つぎのフレームで2ドット=目の大きさが二倍です。
画像生成モデルや動画生成モデルはまさにパン焼き窯みたいなものです。毎回、焼き加減や出来栄えが微妙に変わる。
小さな絵はその微妙な変化をもろに受けます。手作りクッキー並みに細部が微妙に変化する。依然として厳選と仕上げは人間の仕事です。

靴の影と輪郭の手直しと位置調整は必要ですが、左右移動の差分はこれでOKでしょう。
画像作成のワークフロー
うちの環境で実際の手順を追いましょう。
まず、手元で生成モデルを動かすためにComfyuiサーバーを立ち上げます。
つぎにAntigravity製の偽自作ツールもどきを起動します。ほとんどがPythonのStreamlitベースのpyファイルです。
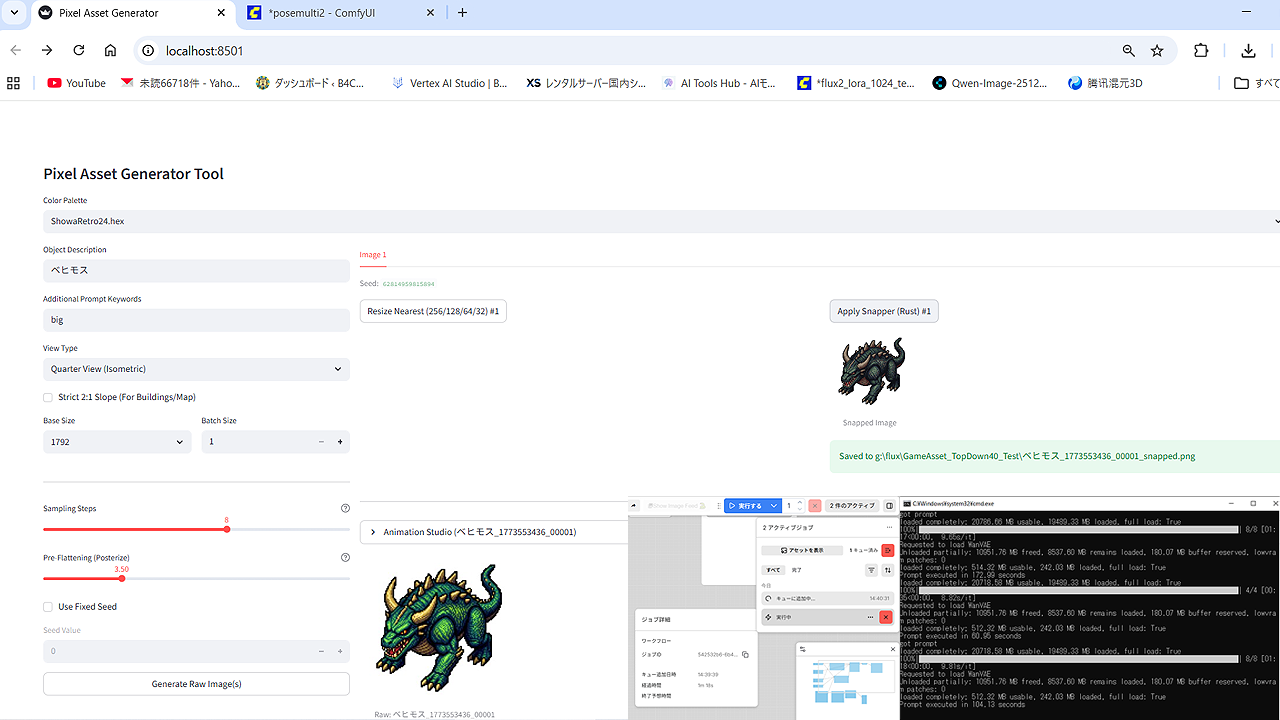
ブラウザからオブジェクトや追加項目を入力して、ポーズのプリセットや各種の数値を選べば、バリバリのドット絵を頂けます。
プロンプトはシンプルです。ポジティブがこれです。
f"pixel art,each pixel is drawn as a 4x4 grid of pixels,{obj_desc}, {additional_prompt}, {view_prompt}, "
f"authentic details, highly legible, {color_p}, "
"solid #FFFFFF white background"{}内は代入の変数です。それ以外が地の文です。
うちの2モデルでは”pixel art”のトリガーでドット絵風スタイルが固まりますが、”each pixel is drawn as a 4×4 grid of pixels”で1ドットが4×4=16pxに近付きます。これが後の加工に効く。
この背景画像ではこのプロンプトの効果が良く分かります。

4×4のタイルの線が残りました。銭湯の壁絵やモザイク画的には合格ですが、ゲームの背景には没です。
おそらく生成ステップのどこかでAIモデルがこの線を引いて、これをグリッドと見なすか、むりやり元絵を割って、ドット絵風に近づけるという処理を挟みます。
で、処理の終了までにこの割れ目が消えないと、こういう没が出来上がります。AIくんの努力の跡? いや、意図的な作為でしょうか?
うちでは背景の生成でこのタイル画現象が良く出ます。他方、キャラでは出ない。
キャンバスの端から端まで一杯一杯に描写するときに、しばしばこのタイル割りをステップの後の方で施して、意図的に残す? プロンプトを守って?
最近のAIは非常に狡猾です。「このクソプロンプトは意味不明でナンセンスだ。でも、ごたごた詰められないようにそれっぽい処理を入れるか!」という論理武装を平気でやる。それだな?!
という深読みではこの4×4うんぬんの効果はやや疑問です。実際、背景では裏目に出ますし。
ネガティブです。
drop shadow, blurry, 3d, anti aliasing,gradient, textures, depth of field, anime style, modern cartoon, cute, chibi, skewed, perspective, text, watermarks, 普通ですね。ちなみにCFGは1-4、デノイズは0.85-1.00くらいです。lora込みの高速4steps版では調整の幅はこのくらいです。
この自作ツールがステータスやプロンプトをConfyuiに投げて、バックエンドでAIモデルが処理を行います。
2512 4steps版で1792×1792ピクセルの8stepの画像の生成は平均120秒です。2分はストレスフリーな生成速度です。
しかし、はて、なんで1792×1792だ? これはこの後のPixel Snapperの処理のためです。
ドット絵にする二つの方法
AIのドット絵風の画像を完全なドット絵にする方法は二つです。
- 一般的なニアレスト縮小
- ドット絵特化のツール
ゲーム素材用のドット絵は8の倍数のサイズで作られます。ファミコン風16×16、SFC32x32、ツクール系48×48など。
前段の雪の学校の絵のキャンバスサイズは512×512です。で、一つのタイルが4×4です。512/4は128です。4分の1縮小で1タイルが1ドットになります。
サイズを128にすれば、ゲーム素材のテンプレ的な64、32、16キャラやオブジェクトとのバランスを数値からざっくり考えられます。
8,16,32,64,128,256,512,1024,2048
これらが理想値です。あら、1792はない? はい、これは定番ではありません。これはぼくのPixel Snapper用の数値です。
実際問題、バキバキのドット絵を得るならば、512×512で生成して、4分の1にニアレスト圧縮、4倍再拡大、減色、再縮小などで取れます。
しかし、この圧縮方式では一つの問題があります。カラーがまとまらない。
Python画像処理ライブラリのPillowの圧縮や減色ではサイズ、カラーを固定できます。しかし、画像内の色の配置をきれいにまとめられません。
これは減色対象のカラーが近似値にむりやりまとめられるからです。肌色の真ん中のハイライト的な白っぽい点がデータでピンクに変わってノイズになるみたいなことが起こる。
Pixel Snapperの弱点
Pixel Snapperは最新のドット絵特化ツールです。ドット絵風ないし普通のイラストを完全な真ドット絵に変換します。
このPixel Snapperの色の配置はより自然です。変なところに変な色がない。カラー数の指定も可能です。
しかし、重大な欠点があります。
- サイズが相対的になる
- パレットがばらつく
上記のように128や64サイズの画像がゲーム素材には合理的です。しかし、Pixel Snapperにサイズの指定機能はありません。
このツールは元の画像のデータの中できれいに1ドット化できそうなやつをドット化して、全体を完全なグリッドタイルにするものです。
簡潔にキャンバスサイズの指定が不可です。「128×128にして」が無理だ。キャンバスサイズは元画像の大きさや描写に左右されます。
一枚の画像に複数の下絵を配置して、Pixel Snapperに通してみましょう。だいたいこういう結果が出ます。

ランダムな1ドットが出るか消えるかでキャラの幅や背が微妙に変わる。で、小さいドット絵ではその影響が如実です。
さらに色数の指定は可ですが、「この色やHEXカラーパレットを使って」は不可です。やはり、カラーは元画像の色味に左右されます。
反面、Pythonライブラリの画像処理ではサイズやカラーの強引な指定は可能です。これは減色用の自作ツールです。
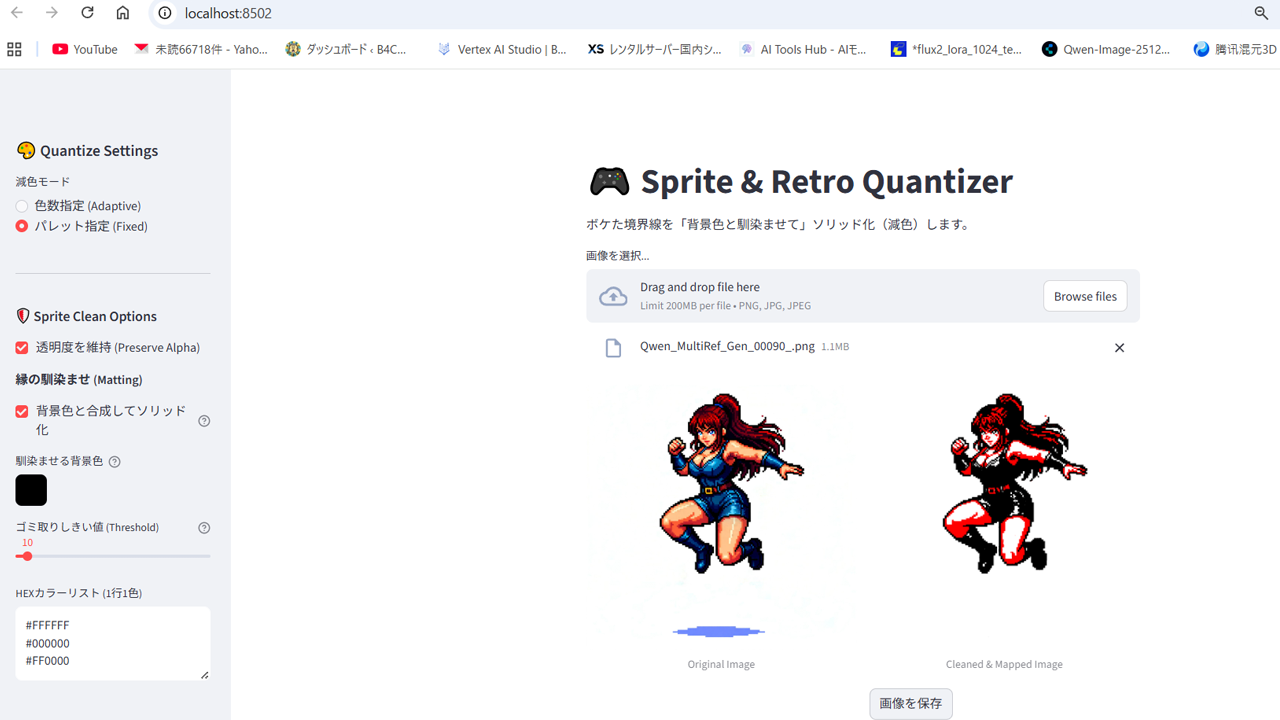
これを逆手に色数を6色くらいにしぼれば、カラー配置のムラをごまかせます、描写のリッチさを犠牲にすれば。
ぼくはあれこれ試して、『Pixel Snapperで128に近い数値を出すには1792×1792で生成する』という結論に至りました。
この環境とツールとプロンプトでQwen 2512にドット絵風のベースを書かせて、Pixel Snapperに通すと、136×136の下書きをほぼほぼゲットできます。まれに135×136とか。
で、これをAsepriteで128×128にクロップする、と。
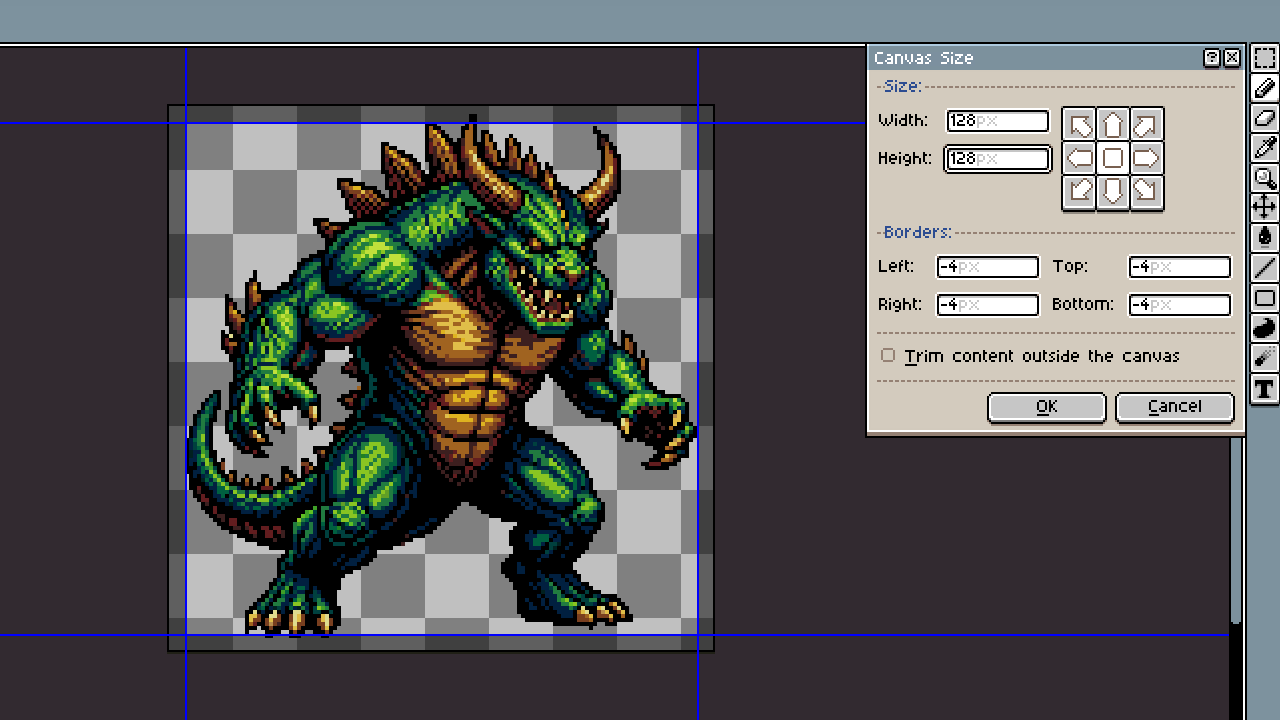
はい、角のさきと爪のさきが欠けました。ちょ、ベヒモス! 爪切り!
ここでついに人間の出番です。角を2ピクセル、爪を1ピクセルほど短くしましょう。
という感じで、うちの環境では128の画像を得るための適正サイズが1792です。
差分作成のコツ
一枚絵のドット絵はワンクリックで完成します。しかし、これの一貫性を保ちながら、ほんの少し別のバージョンを得るのはそう簡単ではありません。
これはポーズや衣装の変更ツールです。
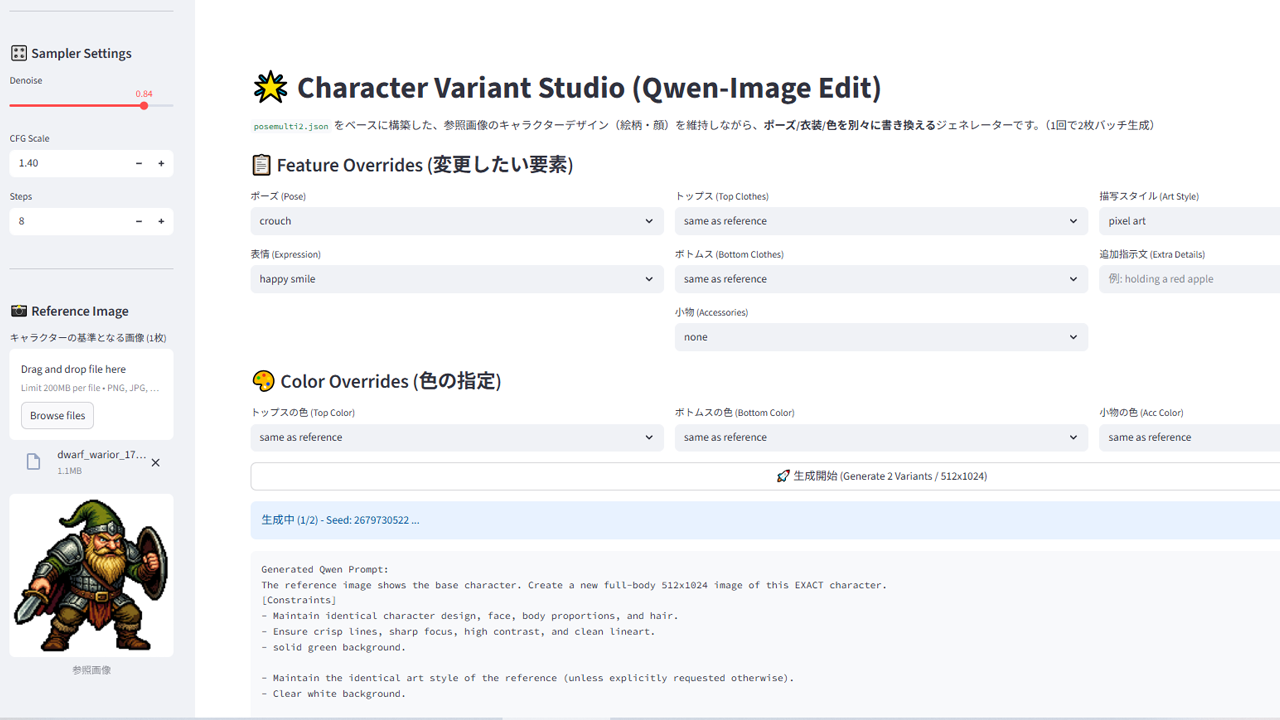
画像生成モデルや動画生成モデルはおおまかな流れをばーっと描いて、細部をちまちま描きます。小さいグリッドを維持しながら、大きな流れを構成するような手法を取らない。
AIのさくせんは基本的に『フルカラーでリッチにガンガンいこうぜ!』です。ドット絵は生成モデル的には重度の縛りプレイです。じゅもんやとくぎなしでボスを倒せ、的な。
- ベース画像から一枚絵のポーズを作る
- ベース画像からモーション全部を一枚絵で書き出す
- CFGを低く、デノイズをきつめにして動画で動かす
これらはもうやりこみプレイです。しかし、このような縛りを設けないと、ドット絵の差分を入手できません。
画像生成モデルも動画生成モデルもすぐに『ガンガンいこうぜ!』に走ります。フル性能を使いたがる。結果、カラーパレットがオーバーキルになります。
個人的なおすすめは動画 > 全モーション一括 > 個別一枚絵です。とにかく生成回数をなるべく減らして、1シーンで複数のストップモーションを得る。
ぼくらの感覚では一つ前のドワーフと一つ後のドワーフは同じですが、AI的な感覚では別バースの別キャラです。前のカラーパレット? は? ナニソレ?
複数モーション一枚絵ではパレットは1つで済みます。
しかし、モーションのベストな絵が一撃ではまず出ない。上の図では右の子だけが合格です。左の裏側の野郎のポーズはOKですが、衣装がなぜか半袖半パン、そして、前のやつがジャマだ。
と、二枚目三枚目が必要になり、カラーパレットや人物の大きさや小物が微妙に変わる。
動画では待機モーションや歩行モーションはわりときれいに出ますが、早い動きの細部は崩れます。とくに走行モーションの指ですね。

走りの差分の作成はまじで難題です。数が8~10枚と多め、動きが大、左右が非対称、足と手の表裏あり、そもそもフォームがかっこよくならない。
このレベルのものを仕上げるにはかなり苦労します。
さっきのベヒモスの攻撃モーションは4Fくらいでまあまあの見栄えになります。こっちの方がぜんぜん楽だ。

まあ、バキバキがやや薄れますし、動き分の横幅がすこし足りません。アニメはムズイ・・・
自宅でドット絵作成するなら
- GPUは大正義
- メモリは64GB
- ストレージは1TB
AIローカル環境では処理速度でもたつくことがいちばんのストレスです。お金を掛けられるなら、24GB以上のGPUと64GBのメモリを最優先で入手しましょう。

