- 完全なドットの作成は可
- キャラクターの差分作成は可
- 簡単なアニメも可
- カラーパレット、色数の固定が難関
AIのドット絵作成、ピクセルアートのDIYの現状はこのような結論です。カラーパレットが当面のエリアボスです。
その他の課題は2025年年末から2026年初頭のツールやモデルの発表でほぼクリアされました。



ぼくは画像編集できますが、絵を描けません。しかし、あれやこれやを駆使すれば、小一時間でこのような素材を作成できます。
また、冬の自転車オフシーズンの合間に自作PCにAI環境をてんこもりに構築したので、いろんなスタイルでいろんなイラストや動画を自由に作れます。
と、プロンプトとモデルでいろいろ作れますが、とくにファミコン世代のど真ん中の思い入れからドット絵の作成を集中的にやりました。で、当面の結論が『カラーがボス』です。
この記事ではドット絵作成のツールやワークフローを紹介します。
ドット絵って?
ドット絵は点(ドット)の絵ですから、広義には点描の一種です。スーラやシニャックが有名です。
で、モニター画面のドットは四角形ですから、モザイク画やタイル画の親戚筋でもあります。ポンペイの遺跡のやつが有名です。
が、ドット絵はぼくらの世代では何より『ゲームの描画方法』を直接的に意味します。ファミコン、スーファミ世代には超おなじみです。
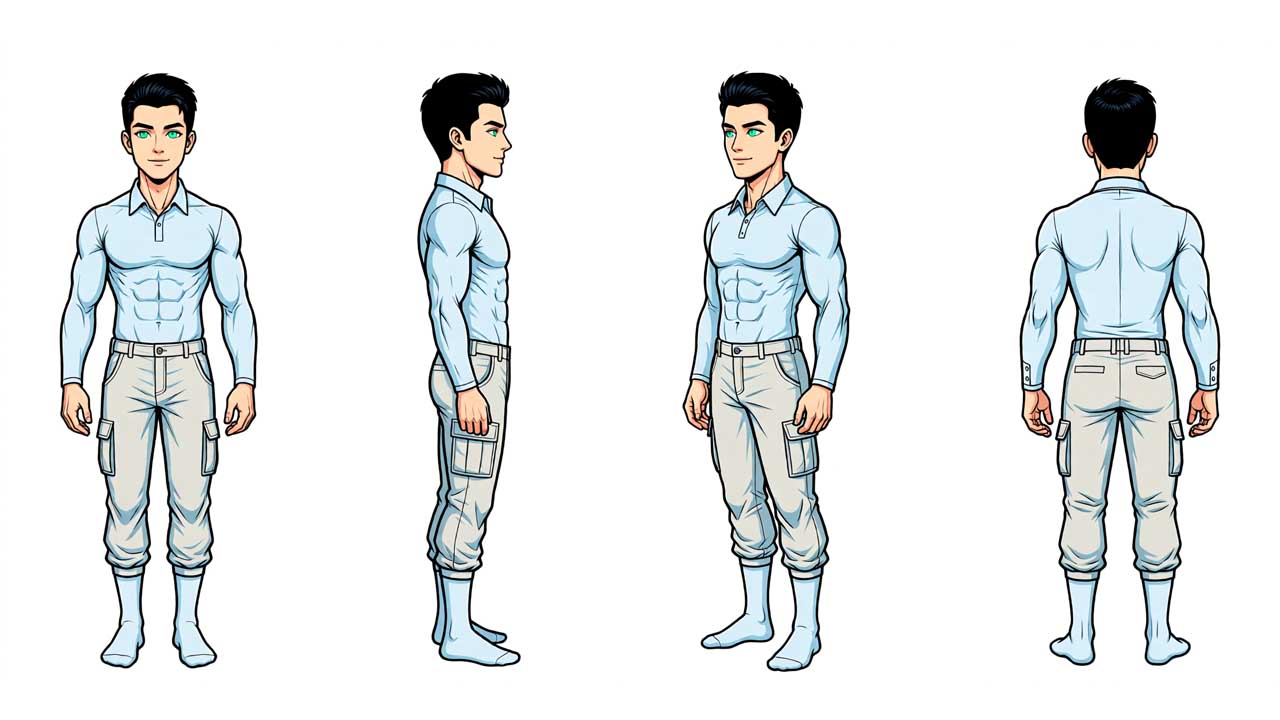
こういうやつです。

これを『ドット絵』と呼ぶか、『ピクセルアート』と言うかでおおよその年代や系譜が分かります。Nvidiaのチップをなんて呼ぶ? グラボ、ビデオカード、GPU? と同じく。
ちなみにドット絵風のカクカクの絵はpixel artで、マインクラフトみたいなカクカクの疑似3D絵はvoxel artです。
AIが作れるのはドット絵風の画像
ドット絵、点描、モザイク画、タイル画は伝統的な手法です。とくに生成AIはゲーム文化の従妹みたいなものですから、生成モデルはこれを学習して、理解します。
GPTやGeminiのNano Bananaのチャットにramen,pixel artなどのプロンプトを打てば、高品質なドット絵風の画像を頂けます。

ラーメンにしいたけ? 和風創作系ですか?
ところで、これはドット絵風の絵で、完全なドット絵ではありません。旧SNKやカプコン、スクエア、アトラスのドット絵師匠の前ではこの似非ドットは確実に不合格です。
理由はカクカクの精度です。上のラーメンのネギorニラを拡大しましょう。

10倍あたりで四角形のエッジがぼやけ、ドットの不揃いと色のにじみが露になります。これはドット絵の定義から外れます。
つまり、AIが作れるのは完全な真ドット絵でなく、ドット絵『風』の画像です。
で、何が違うか?
ドット絵、ピクセルアートの定義
狭義の完全ドット絵、ピクセルアートの定義は以下のようなものです。
- ぼやけない
- にじまない
- ソリッドカラー
- パレット固定
元がゲームの描写方法です。当時のファミコンの性能では1キャラは3色+透明の4色でした。おかげでマリオの目の色は青黒でなく単色の芥子色です。
ここからデジタルグラフィックがリッチになり、8bitや16bitを経て、約1,677万色フルカラーに至りました。
画像生成AIは最近の子ですから、余裕でこのフルカラーを使います。というか、このフルカラーでしか描けません。
生成モデルは「4色で書いて」と指示を受けても、4色ベースのグラデーションをふんだんに使って、100カラーぐらいで4色風に見せます。
上のラーメンのネギも20色くらいのリッチな表現です。遠目には分かりませんが、近影では分かります。で、これがぼやけやにじみになる。
もっとも、ぱっと見は完全なドット絵に見えます。一枚絵として成立する。なんでゲーマーの価値観では不合格になるか? え、古株のマウントですか?
でも、『本場の味 博多とんこつラーメン!』の店で創作系和風あっさりラーメンが出てきたら、文句の一つも出ません?
やはり、通が求めるのは本物です。夏休み前のテスト期間中に勉強をほっぽり出して旧SNS本社前のNEOGEOランドへせっせとKOFのロケテストしに通ったこの口には『風』は薄味ですわ。

まあ、江坂の象徴だったSNKも二駅先の新大阪に移転しましたが。
偽ドット絵の弱点
偽ドット絵の弱点は真ドット絵の裏返しです。
- ぼやける
- にじむ
- カラー数
最近の大作ゲームはフルカラー、フルボイスです。ドット絵はAAAでは過去の産物だ。
しかし、小規模開発やインディーズでは完全ドット絵はまだまだ現役です。フルCGや手書きアニメは個人や零細には圧倒的に重荷だ。
ことさらにカラー数、パレットの色指定は重要です。
これは別のドット絵風の生成画像の編集画面です。赤い点が1ドットです。で、左枠がカラーパレットですが、緑のバリエーションはこんなに要らない。
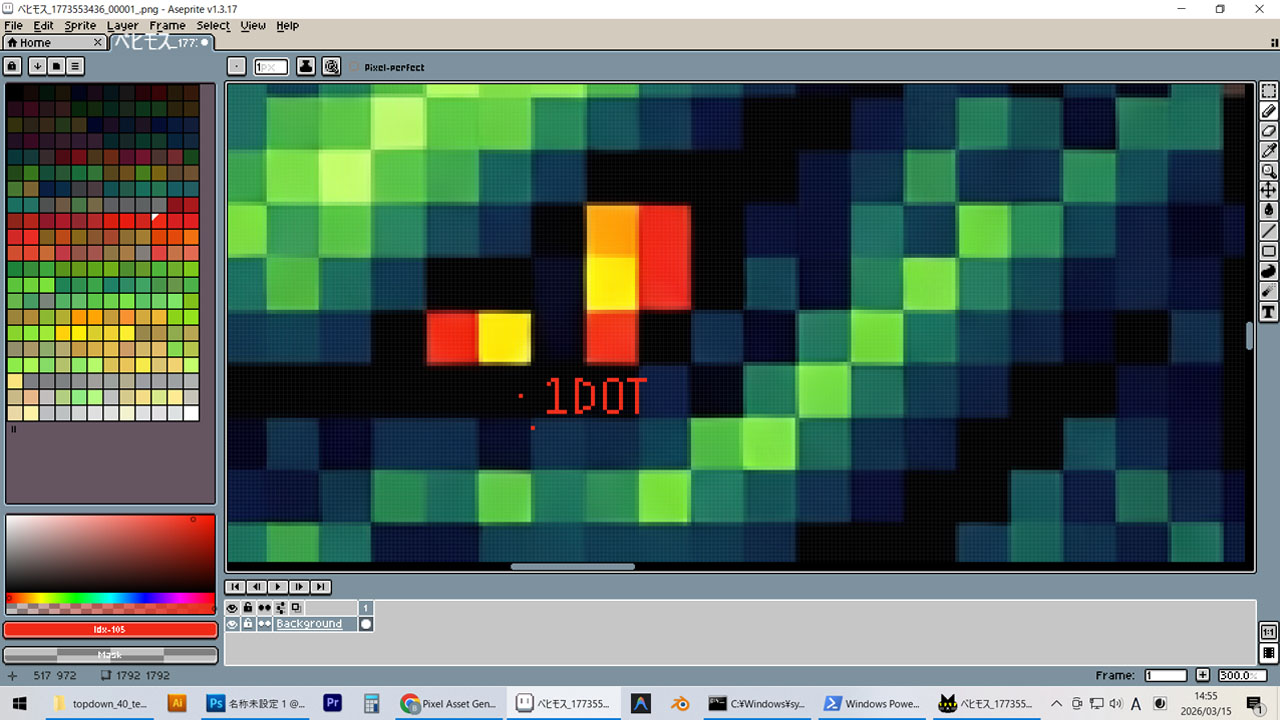
もっとも、これは下書きです。これをベースにして、ドット絵を作ります。ツールでサイズ縮小、減色、背景透過して、有料ソフトのPhotoshopやAsepriteで仕上げます。
カラーはここまで減りました。23+1透過の24です。
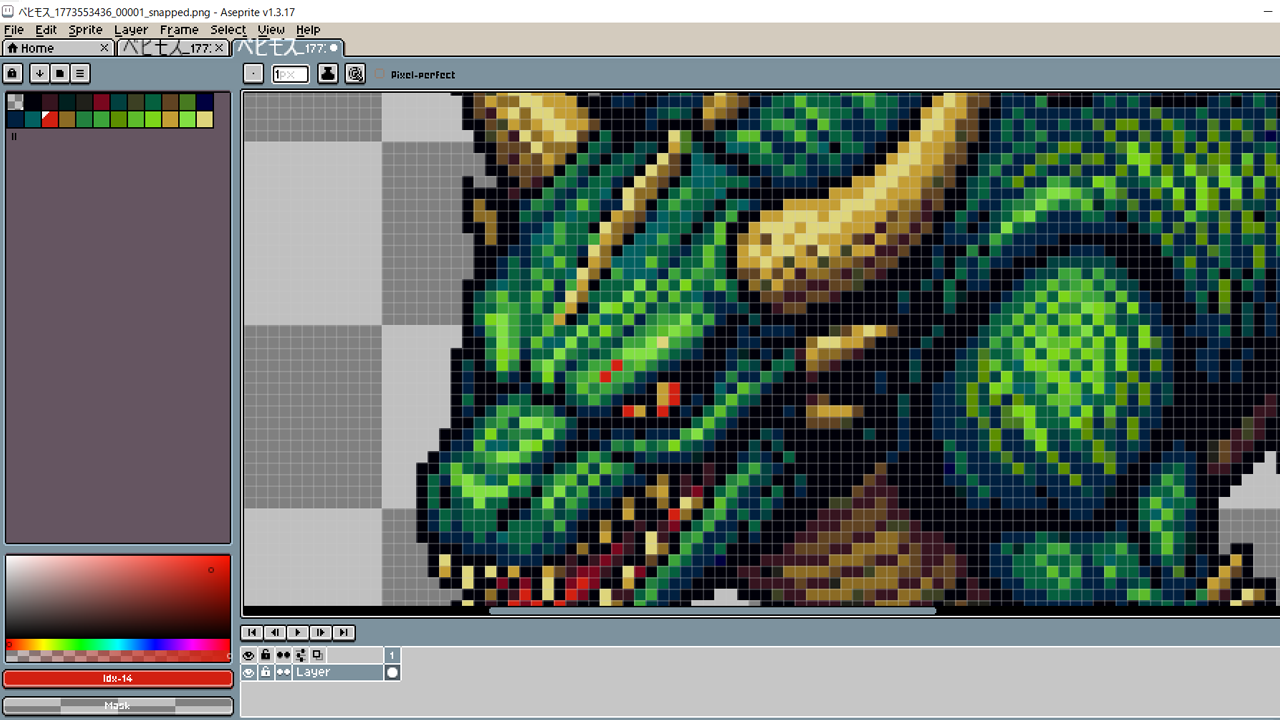
これはうるさい古参ゲーマーやドット絵マイスターに及第点を貰えます。実際、出来栄えは即戦力レベルです。
このようにカラーを少なく絞ると、簡単に色違いのキャラを作れます。これは旧エニックスの十八番です。青いのはスライム、赤いのはスライムベスです。
ただし、これはまれに悲劇を起こします。
初代ドラクエIIIで勇者の父親オルテガはカンダタやさつじんきと同じ上半身裸、覆面、マント、半パン、手斧の変態外見でした。パパスの最期に隠れますが、地味に悲劇です。
オルテガの独自グラフィックはSFCのフィールド版を経て、2025リメイク版で完全鳥山絵になりました。悲劇からざっと30年です。
もっとも、リメイク版オルテガはバキバキのドット絵でなく、はやりのレトロリッチなHD描写です。
AIドット絵の作り方 下準備
AIでドット絵『風』の画像を作るのは簡単です。”pixel art”でスタイルやタッチがそうなります。
ただし、上述のようにこれは完全なドット絵ではありません。この伝統的グラフィックスタイルと画像生成の描写方法は基本的に相反します。
- 色固定
- 背景の透かし
現時点ではこの二つが不可です。AIは透過色を扱えない。背景の切り抜きはプログラムや人間の仕事です。
必要なツール
ここからぼくの実際の手順やツールを紹介します。
PCの構成です。
- GPU RTX3090 VRAM 24GB
- CPU RYZEN 9 5950X
- RAM 32GB
- ストレージ6TB
YouTubeの動画編集自作機にビットコインマイニングの遺産RTX3090を搭載したマシーンです。

3090のVRAM 24GBには20GBクラスのAIモデルを乗せられますから、おおよそ快適に動かせます。しかし、メモリが少し足りない。
ライブラリやソフトです。
- Python
- Git
- CUDA
- Comfyui
この4つは必須です。
次がオプションです。
- Rust ※Pixel Snapper用言語
- Antigravity ※自作ツール作成用アプリ
Pixel Snapperは待望の完全ドット絵作成ツールです。Web版を使うか、Rustをインストールして、オープンソースをDLして、ローカルで動かします。
AntigravityはGoogle製のエージェントツールです。GeminiやClaudeと連携して、ローカル環境の構築や自作ツールの作成に活躍します。
あとは編集ソフトです。
- Photoshop
- Aseprite
Photoshopは大昔の買取版のマスターコレクションですが、ぼくの使い方=ブログの画像やYoutubeのサムネとかでは現役です。
Asepliteはドット絵の編集用の最強ソフトです。1000円くらい。
ドット絵をPhotohopで弄ると、まれに変な透過を入れてしまったり(消去とか境界調整とか)するので、ぼくは基本的にAsepliteで編集します。
で、編集ソフト2種以外はオープンソースorオープンコードです。一応、Antigravityもまだ無料です。AIプランを登録しないと、すぐにクレジット制限を食らっちゃいますが。
正直、この環境は趣味のドット絵作りにはオーバースペックです。
画像生成モデル
オープンソースの画像生成モデルはいろいろあります。かつての王者だったStable Diffusionはやや衰退しました。
描写性能はおそらくGoogleのNano Banana Pro 2が最強ですが、無料枠はせいぜい5枚くらいです。5枚では当たりは出ません。
最近の無料モデルの候補は
- Flux
- Qwen Image
のどちらかです。
FluxはSDの実質的な後継モデルです。ぼくもしばらく使いましたが、バリエーションの多さにひかれて、Qwen系に目移りしました。
QwenはAlibabaのオープンソースです。で、Alibabaはこのブログでは海外通販のAliExpressでもうおなじみです。縁があるね。
Qwenのバージョンをいろいろ試して、結果的に以下の2つに落ち着きました。
- Qwen 2512 steps4 ※主にベース作成
- Qwen 2511 Edit steps4 ※部分書き換えやポーズ変更
2512はカスタム版、2511はEdit版です。どちらもカスタムモデルですが、特性がすこし違います。ちなみに4つの番号は発表年月を表します。2512→2025年12月版。
同じステータス、Seed、pixel art、ベヒモスの生成結果です。


2511 edit版はよりレトロなFC時代のドット絵、ピクトグラムっぽくなります。2512はバッキバキのゴリゴリドット絵です。
この差は偶然ではありません。100枚ほどの実験でこの傾向が共通します。”pixel art”のトリガーで出る傾向がこうなる。

なんか2511 edit版には2025年下旬に海外のSNSで流行ったピクセルアートスタンプぽいスタイルが強くかかるように思えます。
このようにバージョンが変われば、結果がガラッと変わります。
ぼくは旧SNKのメタルスラッグ的なゴリゴリドットを推しますので、基本的に2512で生成します。以下のサンプルも2512の産物です。
しかし、2512は書き換えには不向きです。edit版でないからか? 正式ファイル名は
qwen_image_2512_fp8_e4m3fn_scaled_comfyui_4steps_v1.0.safetensors
です。現状の最新モデルぽい。
これにモーションの差分の出すための動画生成モデルを併用します。
- Wan2.2
- Hunyuan Video 1.5
WanはQwenと同じくAlibabaのオープンソースです。しかし、うちの環境では何かうまく動きません。良い絵が出ない。
HunyuanはTencentのモデルです。ぼくはドット絵のアニメの作成にはこちらを使います。
それか、簡単なモーションを一枚のキャンバスで一気に書くか。
しかし、個々でそれぞれの難所があります。
- 複数動作を一枚で描かせる→細部が崩れる
- 動画で動かす→生成時間が伸びる
- 精細なストップモーションをposeやキャニーで個別で作る→色が変わる
今のところ、ぼくは一貫性を重視して、2の手法を主に使います。で、不足分のフレームを3で作って、カラーを手動で合わせる。
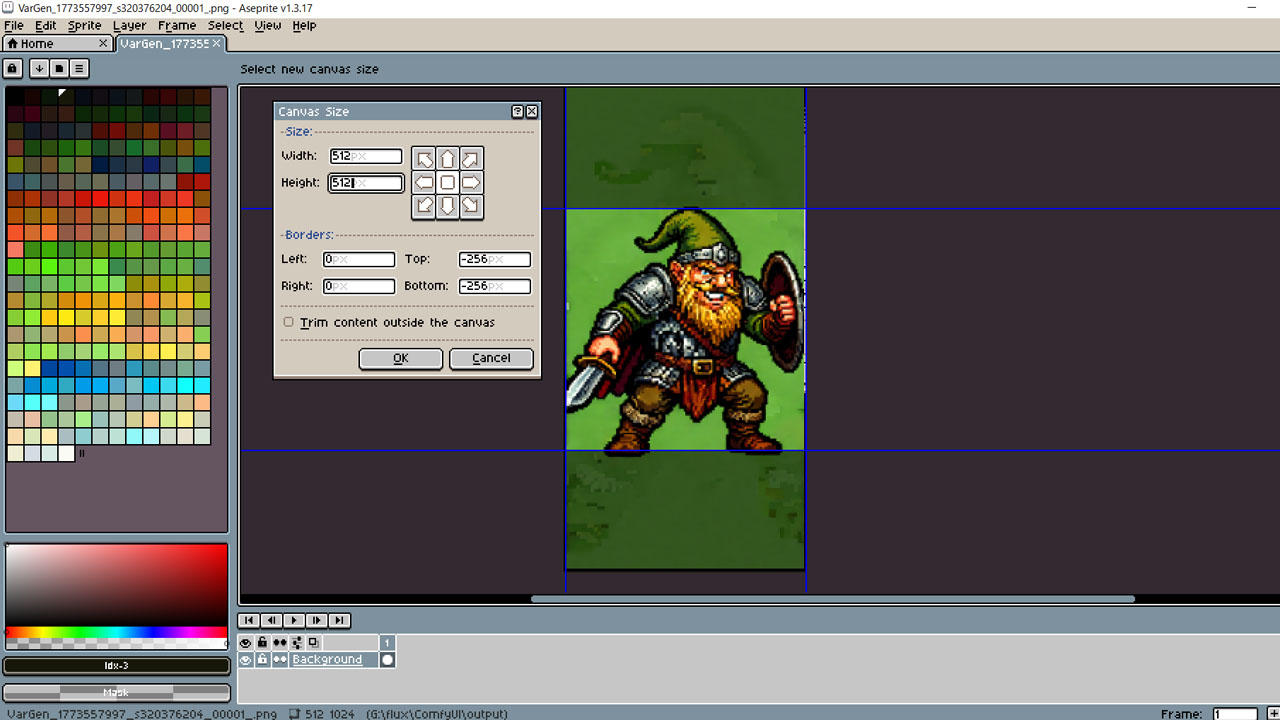
上のドワーフさんの歩行モーションは動画でほぼそろいました。ここからツールで全フレーム(4f飛ばしくらいで)を切り出して、いいとこだけを抽出します。

靴の影と輪郭の手直しと位置調整は必要ですが、左右移動の差分はこれでOKでしょう。
画像作成のワークフロー
うちの環境で実際の手順を追いましょう。
まず、手元で生成モデルを動かすためにComfyuiサーバーを立ち上げます。
つぎにAntigravity製の偽自作ツールを起動します。ほとんどがPythonのStreamlitです。
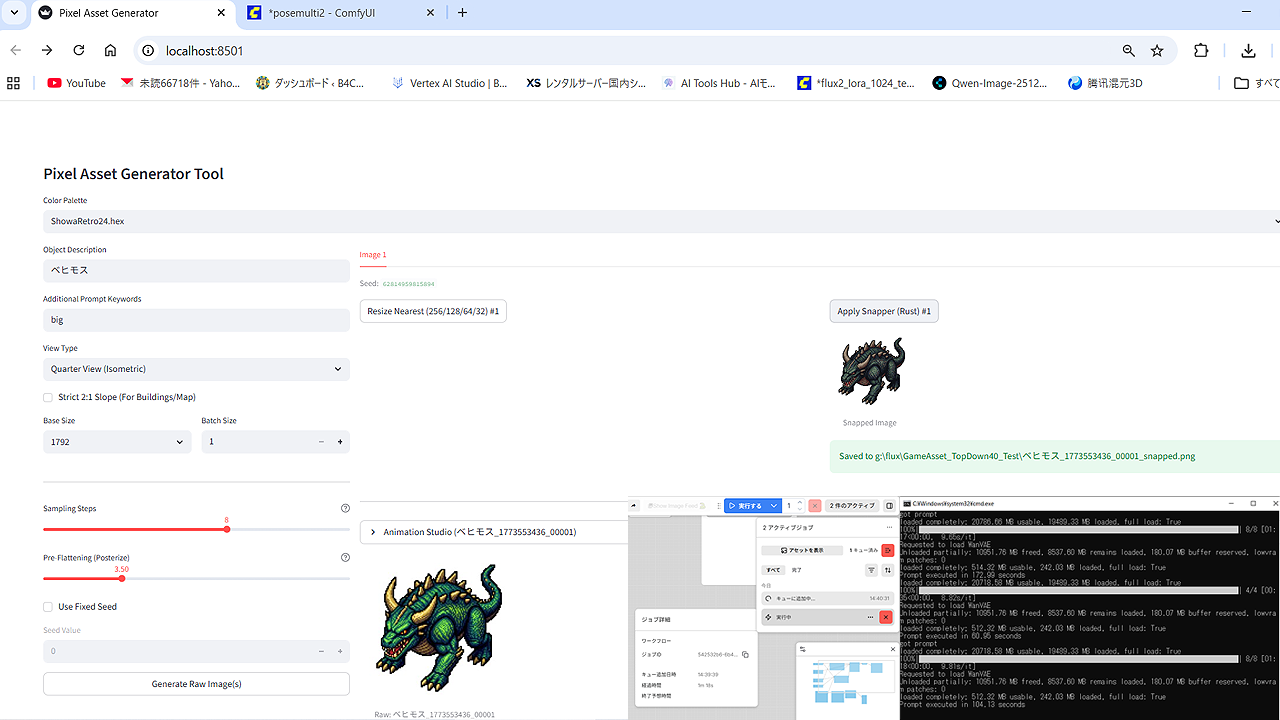
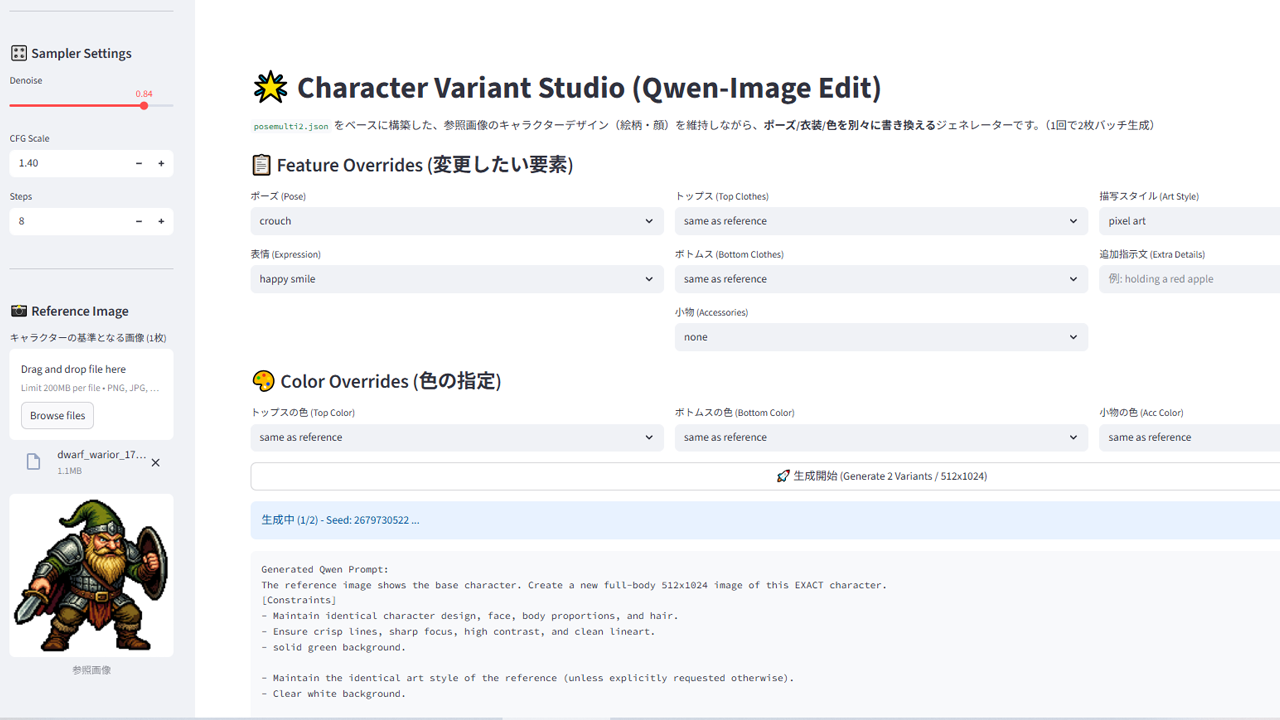
ブラウザからオブジェクトや追加項目を入力して、ポーズのプリセットや各種の数値を選べば、バリバリのドット絵を頂けます。
プロンプトはシンプルです。ポジティブがこれです。
f"pixel art,each pixel is drawn as a 4x4 grid of pixels,{obj_desc}, {additional_prompt}, {view_prompt}, "
f"authentic details, highly legible, {color_p}, "
"solid #FFFFFF white background"“pixel art”のトリガーでドット絵風スタイルが固まりますが、”each pixel is drawn as a 4×4 grid of pixels”で1ドットが4×4=16pxに近付きます。これが後の加工に効く。
背景画像の没ではこのプロンプトの効果が良く分かります。

4×4のタイルの線が残りました。モザイク画的には合格です。
おそらく生成ステップのどこかでAIモデルがこの線を引いて、これをグリッドと見なすか、むりやり元絵を割って、ドット絵風に近づけるという処理が挟まれます。
で、生成処理の間にこの割れ目が消えきらないと、こういう没が出来上がります。AIくんの努力の跡でしょうか。
ネガティブです。
drop shadow, blurry, 3d, anti aliasing,gradient, textures, depth of field, anime style, modern cartoon, cute, chibi, skewed, perspective, text, watermarks,普通ですね。ちなみにCFGは1-4、デノイズは0.85-1.00くらいです。4steps版では調整の幅はこのくらいです。
ツールの背後ではConfyが動いて、進行が見えます。Qwen IMAGE 2512 4steps版で1792×1792ピクセルの8stepの画像の生成は平均120秒です。
なんで1792×1792だ? これはこの後のPixel Snapperの処理のためです。
ドット絵にする二つの方法
AIのドット絵風の画像を完全なドット絵にする方法は二つです。
- ニアレスト縮小
- Pixel Snapper
うえのツールには両方の機能があります。
ゲーム素材用のドット絵は8の倍数のサイズで作られます。ファミコン風16×16、SFC32x32、ツクール系48×48など。
で、ドット絵への縮小を考えると、ベースを8倍数にするのは合理的です。
上の没の雪の学校の背景は512×512です。で、タイルが4×4です。512/4は128です。これで1タイルが1ドットになります。
で、サイズを128にすれば、64、32、16キャラやオブジェクトとのバランスを数値からざっくり考えられます。
ニアレスト縮小の問題
ニアレストで圧縮してドット絵化するには8の倍数が合理的です。
8,16,32,64,128,256,512,1024,2048
あら、1792はない? はい、これは定番ではありません。これはぼくのPixel Snapper用の数値です。
実際問題、バキバキのドット絵を得るならば、512×512で生成して、4分の1にニアレスト圧縮、4倍再拡大、減色、再縮小などで取れます。
しかし、この圧縮方式では一つの問題があります。カラーがまとまらない。
このカラーのまとまりはカラーパレットのことではありません。画像内の描写カラーの配置のことです。
Python画像処理ライブラリのPillowの圧縮や減色ではサイズ、カラーを固定できます。しかし、画像内の色の配置をきれいにまとめられません。
これは減色対象のカラーが近似値にむりやりまとめられるからです。肌色の真ん中のノイズ的な青ぽい紫の点がデータで赤に変わってノイズになるみたいなことが起こる。
Pixel Snapperの弱点
一方、Pixel Snapperの色の配置は自然です。変なところに変な色がない。カラー数の指定も可能です。しかし、サイズの指定とパレットの固定が無理だ。
Pixel Snapperは最新のドット絵作成ツールです。ドット絵風ないし普通のイラストを完全な真ドット絵に変換します。オープンソースです。
ぼくはこれをローカルに入れて、ニアレストと併用します。理想のドット絵環境です。しかし、この素晴らしいソフトは完璧ではありません。
- サイズが相対的になる
- パレットがばらつく
上記のように128や64サイズの画像がゲーム素材には合理的です。しかし、Pixel Snapperにサイズの指定機能はありません。
このツールは元の画像のデータの中できれいに1ドット化できそうなやつをドット化して、全体を完全なグリッドタイルにするものです。
簡潔にキャンパスサイズの指定が不可です。「128×128にして」が無理だ。サイズは元画像の大きさや描写に寄ります。
さらにカラーの数の指定は可ですが、「この色やHEXカラーパレットを使って」は不可です。やはり、カラーは元画像の色味に寄ります。
反面、Pythonライブラリの画像処理ではサイズやカラーの強引な指定は可能です。これは減色用の自作ツールです。
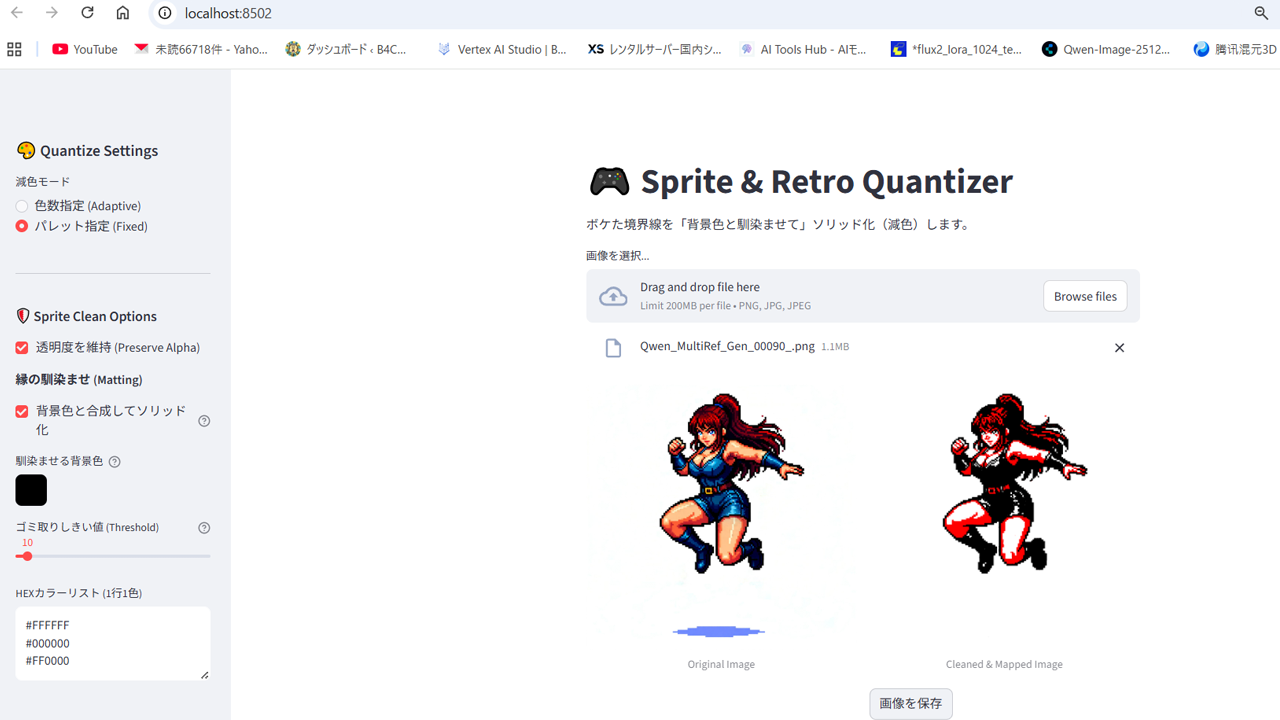
これを逆手に色数を6色くらいにしぼれば、カラー配置をうまくごまかせます、描写のリッチさを犠牲にして。
で、ぼくはあれこれいろいろ試して、Pixel Snapperで128に近い数値を出すためには1792×1792で生成するという結論に至りました。
この環境とツールとプロンプトでQwen 2512にドット絵風のベースを書かせて、Pixel Snapperに通すと、95%で136×136の下書きをゲットできます。
で、これをAsepriteで128×128にクロップする、と。
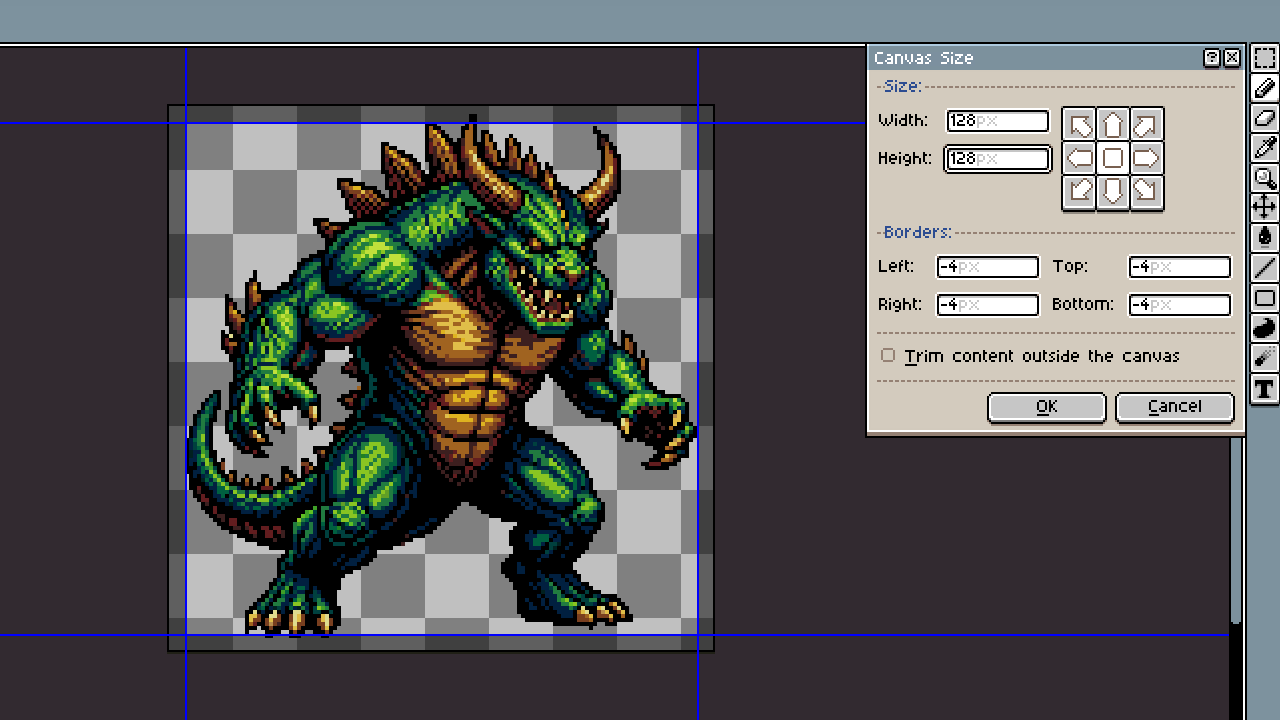
はい、角のさきと爪のさきが欠けました。ちょ、ベヒモス! 爪切り!
ここでついに人間の出番です。角を2ピクセル、爪を1ピクセルほど短くしましょう。
という感じで、うちの環境では128の画像を得るための適正サイズが1792です。
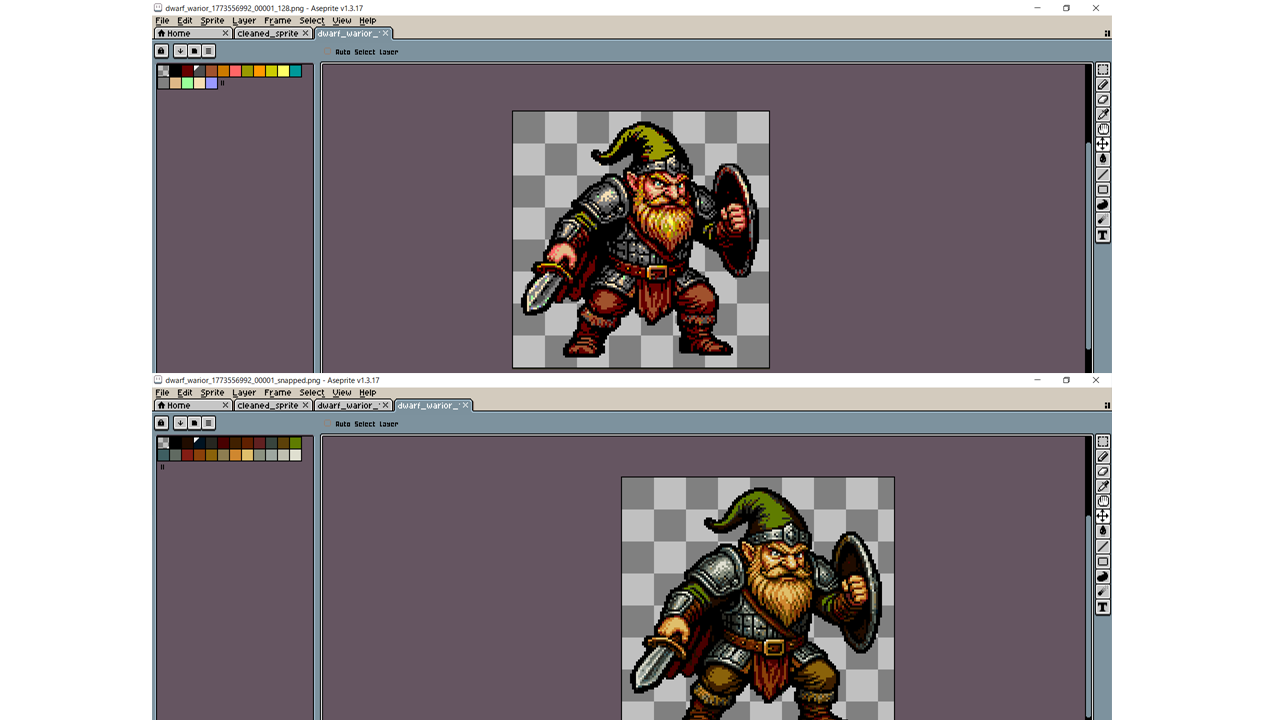
差分作成のコツ
一枚絵のドット絵はポチポチで完成します。これの一貫性を保ちながら、ほんの少し別のバージョンを得るのはまたまた難題です。
画像生成モデルと同じく動画生成モデルもおおまかな流れをばーっと描いて、細部をちまちま描きます。グリッドを維持しながら、流れを構成するようなフローをよしとしない。
ドット絵もそのアイドルモーションも生成モデル的には重度の縛りプレイです。魔法とスキルなしでボスを倒せ、的な。
これをさせずに限定的な差分生成を強要しましょう。方法は3つです。
- ベース画像から一枚絵のポーズを作る
- ベース画像からモーション全部を一枚絵で書き出す
- CFGを低く、デノイズを高めにして動画で動かす
個人的なおすすめは動画 > 全モーション > 一枚絵です。カラーのばらけが深刻だ。
ぼくらの感覚では一つ前のドワーフと一つ後のドワーフは同じですが、AI的な感覚では別次元の別個人です。前のカラーパレット? は?
一枚絵ではパレットは1つで済みます。しかし、モーションのベストな絵が一撃ではまず出ない。と、二枚目三枚目が必要になり、カラーパレットや人物の大きさや小物が微妙に変わる。
動画では待機モーションや歩行モーションはきれいに出ますが、早い動きの細部は崩れます。とくに走行モーションの指ですね。

走りの差分の作成はまじで難題です。数が8~10枚と多め、動きが大、左右が非対称、足と手の表裏あり、そもそもフォームがかっこよくならない。
さっきのベヒモスの攻撃モーションは4Fくらいでまあまあの見栄えになります。

動き分の横幅がすこし足りませんな。アニメはムズイ・・・
自宅でドット絵作成するなら
- GPUは大正義
- メモリは64GB
- ストレージは1TB
AIローカル環境では処理速度でもたつくことがいちばんのストレスです。お金を掛けられるなら、24GB以上のGPUと64GBのメモリを最優先で入手しましょう。