
Elevenlabsは音声の自動生成サービスです。ブラウザからテキストを入力すると、会話や効果音を作成できます。
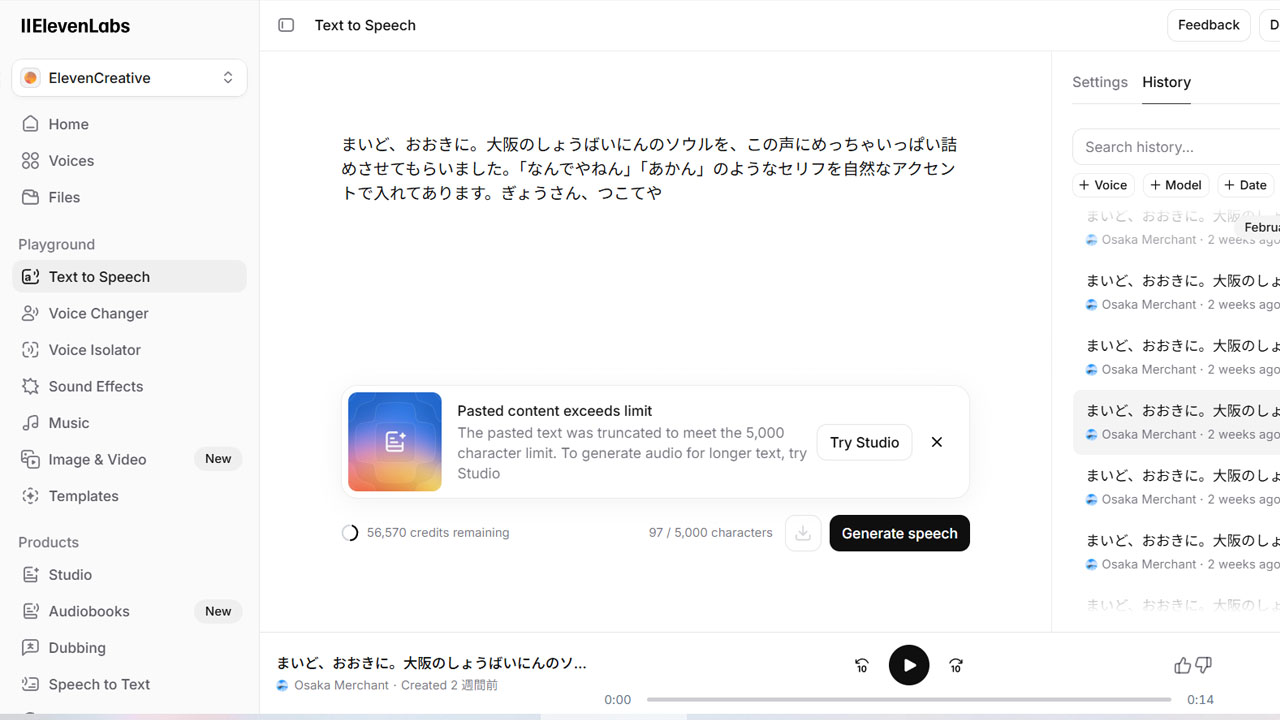
実際の作例です。ぼくの声をクローン化して、紹介文を生成しました。
ぼくはYouTube用の動画を自分で編集しますから、このやや甲高い鼻声を世界中の誰よりきっと多く耳にしますが、オリジナルとこのAIのクローンの差を判別できません。完全にB4Cの声です。
AI音声のクオリティはほぼ完成
言語、動画、画像、3Dモデル・・・AI生成物はネットの海におびただしく漂いますが、ザ・ピンキリです。
画像は一貫性を欠き、動画は割高、3Dは粗削り、言語はハルシネーションを起こすし、時事ネタやニュースやミームを知らない。
一方、会話や音楽、サウンドの生成はほぼ完成の域に達しました。ニッチな自転車YouTuberをかれこれ8年ほど続けるぼくが太鼓判を押します。両者の違いを聞き分けられません。
ただし、関西弁の微妙な抑揚はまだ未完成です。「なんでやねん」は完璧ですが、「まいど、おおきに」はやや微妙、「ぎょうさん、つこてや」はうまく出ない。
え、この言葉が分からない? 漢字で『仰山使てや』で、『たくさん使ってね』を表します。より正確には「ようさんつこてや」ですが、これはもうこてこての浪速っ子以外には伝わりません。
そのほかの部分はほぼ完璧です。商用レベル、業務用クオリティ。実際、ゲーム開発の現場ではサウンドデータのAIの活用が最も効果的だったというレポートがあります。
逆に画像や3Dモデルの生成物は効率化にはまだ劇的に貢献しません。手直しの余地が大です。問題はとにもかくにも一貫性です。
画像、動画生成の問題点
少し脱線しましょう。ぼくの最近の趣味はゲーム素材用の完全ドット絵の作成です。
以下は同じseed値、同じsteps数、同じモデル(Qwen Image 2509)での画像の実例です。自作PCにAI環境を構築したので、制限なしで生成できます。
“MTB in Mountain”のバリエーションです。

一枚一枚のクオリティは上々です。ドットも完全グリッドだ。スーファミのオープンニングには充分でしょう。
が、同じプロンプトに天気の”sunny”とか時間”morning”などの指示が入ると、服や自転車の色、アングルがバラけます。
極め付きに”rainy”にはなぜか自転車が描写されません。画像生成モデルの記憶に雨の日のMTBのサンプルの学習ベースがなかったか。
たしかにMTBerは雨の日のライドの写真をわざわざ撮影しないし、アップしない。
逆に雨の山の絵のサンプルは豊富です。そこからドット絵のステップだけが進んで、MTBが書き込まれなかった・・・って感じ?
アニメです。一枚絵から動画を作って、コード処理で色数固定、全フレーム抜き出してドット化、解像度・FPSを下げました。これでスーファミ風のカクカクなイベントシーンが仕上がります。

背景がざらつくのは許容範囲、MTBをこんなふうヤカンみたいに運べないというのは自転車乗り的粗探しですが、一歩目の踏み出しで足首が消えます。これは一目瞭然です。
と、画像や動画では一貫性の問題がボトムネックですが、音声ではこれがほぼ解決されました。筆頭はテキストから人の声を生成できるElevenlabsです。
Elevenlabsの使い方 基本からクローン作成まで
Elevenlabsの基本情報です。
| 🏢 社名 | ElevenLabs |
|---|---|
| 🔢 バージョン | ElevenLabs V3 |
| 🆓 無料版 | あり (月間1万文字) |
| 💰 基本料金 | $5.00 / 月 |
| 💎 上位プラン | Creator $22 / 月 Pro $99 / 月 |
| 💻 特化領域 | 感情表現ナレーション / 音声翻訳 / SFX生成 |
テキストの音声化、効果音の作成、簡単なボイスモデルのデザインは無料で可能です。
本格的なクローンモデル作成、商用利用、大量のデータの作成などは無料では不可です。とくにクレジットの量が全く足りません。
無料プランで出来ること
無料プランの”10k credits per month”は半角英字ベースの換算です。日本語の全角 > 1クレジットですから、文字数ベースの生成量は8割くらいになります。
300文字で1分のナレーションのテキスト量というのが一般的な目安です。Elevenlabsの無料枠で作れる音声はざっと30分くらいです。
もちろん、全部の生成物が完璧ではありません。正味、ぼくは上のサンプルボイスの「なんでやねん」のアクセントを出すために10回ほどの試行錯誤をしました。
97×10=970 caractersで二つ三つの当たりが出ます。まさにガチャ。採用率は3割ほどです。つまり、無料枠では10分動画1本分のナレーションが限度です。
使い回しの案内音声や挨拶の定型文、効果音はこの限りではありません。
自然な日本語の作り方
Elevenlabsは英語圏のサービスです。本部はロンドンにあります。そもそもAIの開発や学習のベースが英語です。
で、アジアの外れのマイナーな言語への対応は後回しの後回しになります。実際、先代のV2の多言語モデルは漢字をうまく読み上げられません。
上のサンプルでは「まいど」や「しょうばいにん」がひらがなです。とくに「商売人」の読みが「しゅんまいにん?」みたいに中華系になります。
また、「まいどおおきに」はしばしば「マイドーキニ」みたいにリエゾンしてしまう。適度に「、」読点で区切れば、これを封印できます。
結果、直打ちプロンプトは小1の文章みたいになります。
V3モデルで漢字の読み上げの精度が向上
で、ぼくがこの声のサンプルで試行錯誤する最中に最新のアップデートが来ます。ElevenlabsのV3モデルの登場です。
これの漢字含む日本語の読み上げ精度は抜群です。95%ほどを自然に読み上げます。特殊読みや省略以外はほぼクリアです。
ただし、クローンモデルの音声の再現がまだ不完全です。読み上げは自然ですが、肝心の声がB4Cクローンになりません。平均なサンプルボイスみたいなやつになる。
これはぼくのボイスではない。どこのイケメンお兄さんですか? で、あよざん?
このProfessionalクローンのV3モデルへの対応の遅れは公式ページで言及されます。「V2か簡易クローンを使ってね」ということです。
はよ、対応して。
便利なEnhanced機能
V3モデルから読み上げの強化機能が強化されました。Enhancedがそれです。これをぽちぽちすると、[]付きのタグが入力位置に挿入されます。
[laugh] や[whispers]みたいな英単語プロンプトでそのセクションのニュアンスが笑い声やささやきに変化します。
Enhancedタグのポイントです。
- []で囲んで文の前に置く
- 指示は英単語のプロンプトで
- Enhancedタグの効果は次のタグまで継続する
- 併用化
スライダーが簡易に
V2の設定はごちゃごちゃのごてごてで、一見さんにはちんぷんかんぷんでしたが、V3ではプリセットの簡易型になりました。
- 元の音声の特徴を厳密に保持する=Robust
- ノーマル=Natural
- アレンジ=Creative
プラス言語上書きの有無です。
V2でオート化のめどが立った? とにかく、簡易化は大助かりです。クレジットの無駄打ちが減る。MTBのサスの調整もそうですが、プリセットが便利です。詳細設定は底なし沼だ。

Elevenlabsでクローンを作る
Elevenlabsの実力を試すならば、無料枠で存分に味わえます。ぼくは試し過ぎて、クレジットを溶かしてしまい、さらに欲を出して、Creatorプランに加入しました。
Creatorでは本格的なボイスのクローニングとシェアが可能です。ぼくの音声を学習させて、チューニングモデルを公開し、商用利用や収益化を実現できます。
Creatorプランの基本料金は22ドルですが、キャンペーンで初月50%オフの11ドルです。さて、ちゃりんちゃりんで元を取れるか?!
クローンの作り方
クローンの作り方の手順は以下の通りです。
ホーム→Create Voice→Professional Voice Clone
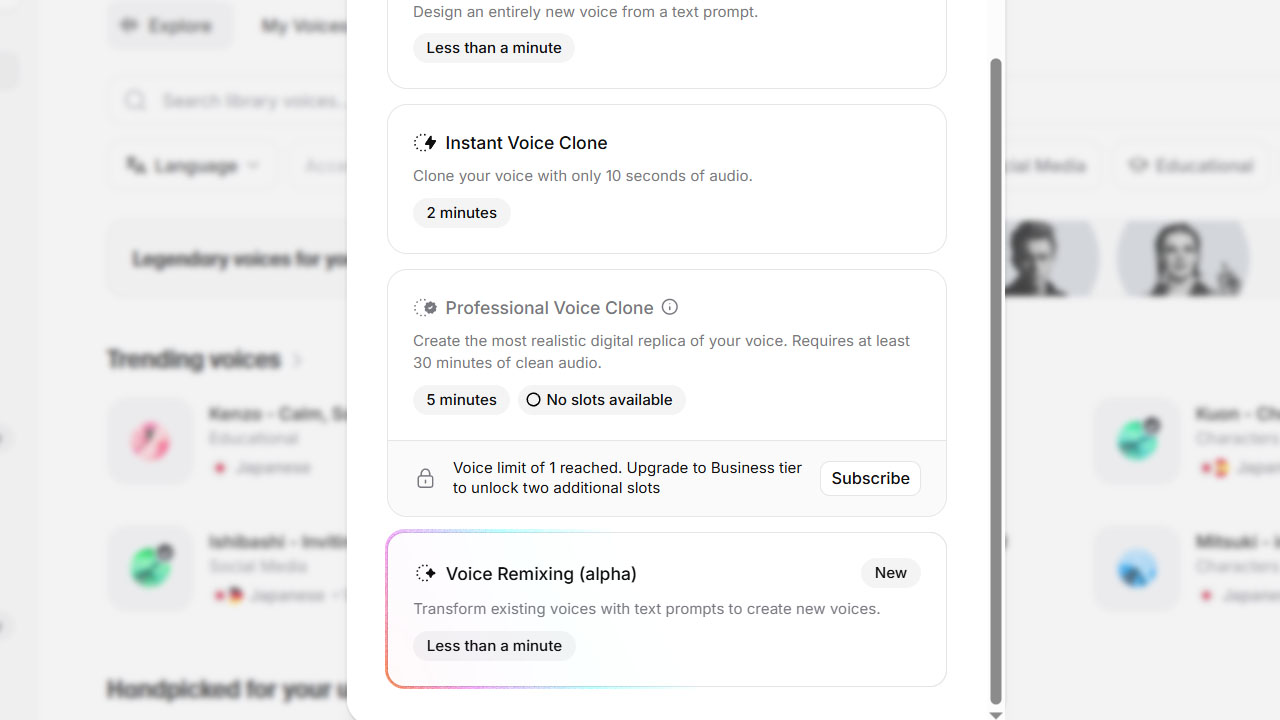
Creatorプランでは1つ、最上位の99ドルProでは5つのProfessional Voice Cloneを登録できます。
Instant Voice Cloneはより手軽なチューニングです。2、3分の音声を上げれば、そこそこのクオリティのクローンを作れます。
ただし、このプランではElevenlabsのプラットフォームで公開して、ちゃりんちゃりんできません。本格チューニングモデルの作成と登録はCreator以上の特権です。
で、ほんまにその声が金になるけ?
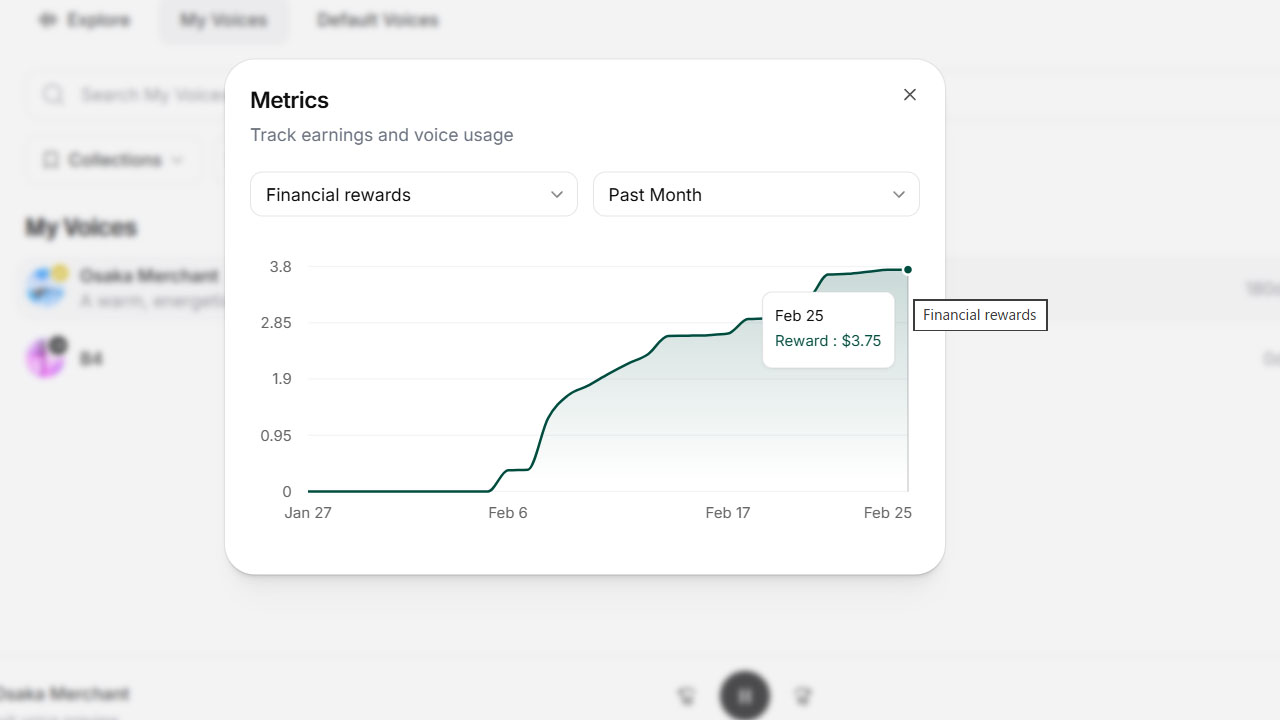
なった! 勝った! しかし、まだ赤字! ぎょうさんつこてや!
学習ベースの音声の注意点
Professionalクローンの作成には十分なサンプルが必要です。推奨は60分以上のクリアな音声です。
さいわいぼくの手元には大量の過去動画の音声データがあります。これらから学習サンプルを抜粋します。
- ホワイトノイズなし
- 環境音なし
- ラウドネス一定(premiereとかで調整)
- 自然な話し言葉やアクセントを入れる
- 小さめファイルにしましょう
ベースは朗読みたいな音声より自然な会話の方がベターです。なぜなら、フォーマルな本読みはある種の演技、『盛り』です。自然にならない、というかナレーション風になる。
それから、ぼくは関西弁の特徴を出すためによりこてこての大阪の下町風のアクセントを多めに入れました。十三の繁華街仕込みの商売人口調です。
あと、数字読み上げ、アルファベット読み上げ、五十音読み上げなどを気休めに新規で収録しました。
で、豊富なwavファイルを用意して、アップロードしましたが、途中で容量規制とファイル数規制に引か刈りました。もう少し軽いmp3形式が正解だったかも
結果的に正味のデータの長さは110分くらいになりました。限度は3時間です。
これらをアップして、ぼんやりと待ちます。チューニングの目安はおおむね数時間です。言語系でも音声でもだいたいそのくらいです。
で、ほぼ3時間で例のB4Cクローンボイスが誕生しました。
- テキストから音声作成
- テキストファイルから音声作成
- 英語のテキストファイルからぼくの声のグローバル版音声作成
YouTubeの海外展開が捗ります。
ためしに最近の自転車のチェーンのメンテ動画を音声分析にかけて、日本語テキストを抜き出し、それをアップして、クローンに読ませました。
B4Cさん、英語ぺらぺらですね!
無論、ぼくはこんなに喋れません。しかし、ぼくの英語の発音がこうなろうというのが良く分かります。ヒアリングやシャドーイングの練習になりますね。
収益化する
では、Professiona Cloneを公開して、収益化しましょう。
Home→Voices→My Voices→指定のボイスの三点リーダー→Share Voiceです。
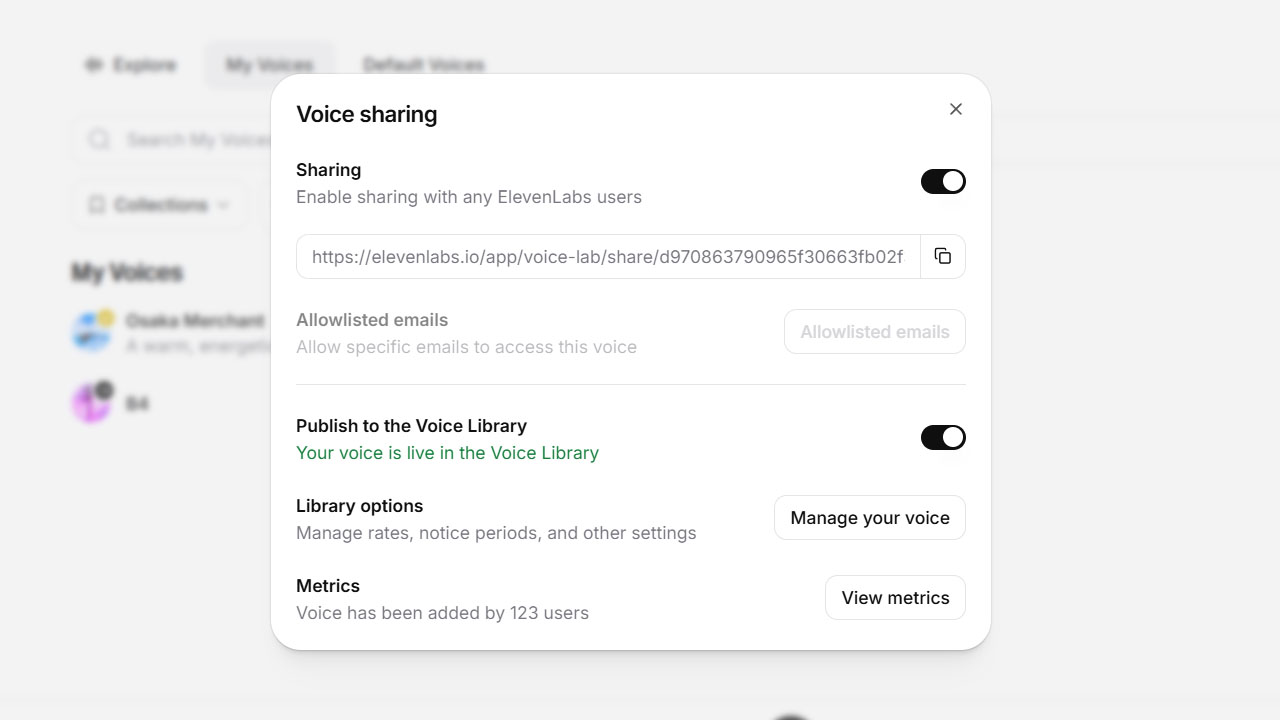
Sharingは公開先のURLです。これが登録されると、”Metrics”の”users”が増えます。現在のぼくのフォロワーは123名です。
で、このボイスが使用されると、クレジット分の配分が行われ、ちゃりんちゃりんが発生します。ぼくの計算では300人くらいで11ドルの元を取れる・・・はず。
シェアの便利な機能
公開するときには名前や紹介文を書けますが、是非にライブラリオプションを設定しましょう。
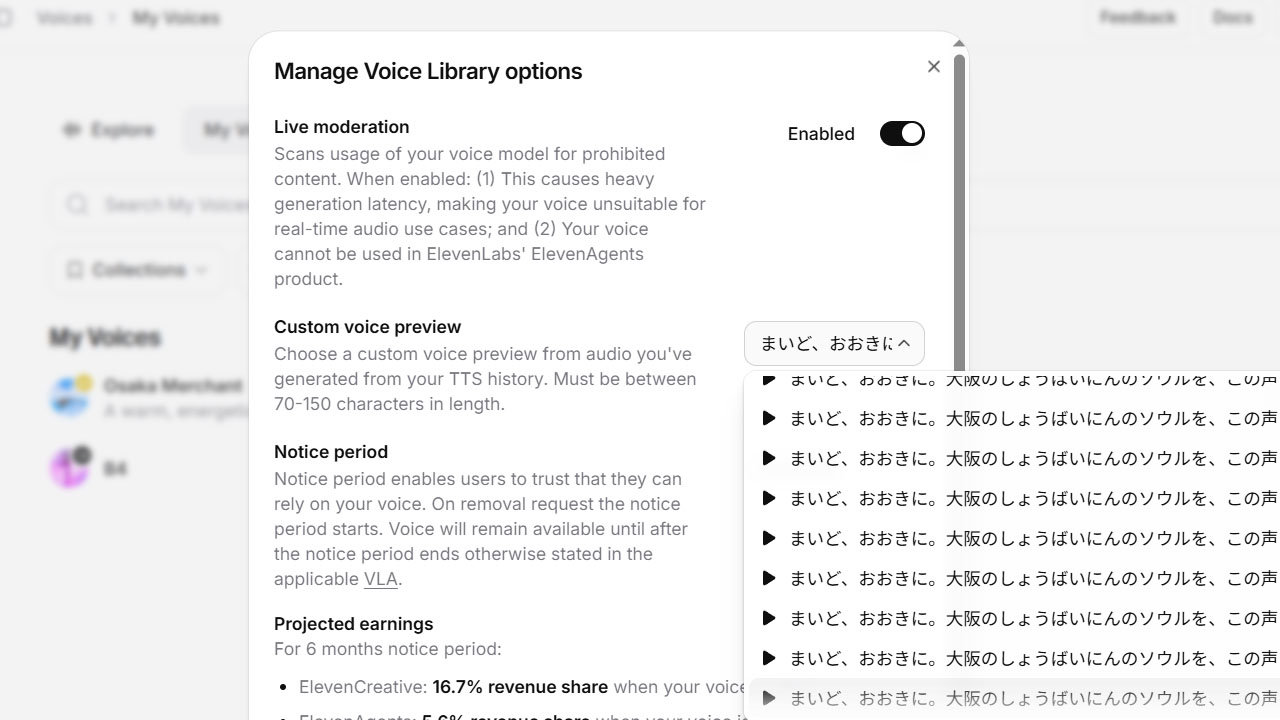
公開時の初期状態ではモデルはプリセットの共通のサンプルの文章を機械的に読み上げます。これは埋もれてしまうし、特徴を消される。プリセットに「なんでやねん」はない。
一方、ライブラリオプションで当たりのやつを選べば、その声と内容をユーザーに直感的に伝えられます。やはり、関西人として本場の「なんでやねん」のクオリティをお届けしなければ。
実際、登録者数の伸びが改善しました。1000人が当面の目標です。
Trending Voicesの一位になりました
公開から2か月後にこのvoiceがtrendingの一位に輝きました。
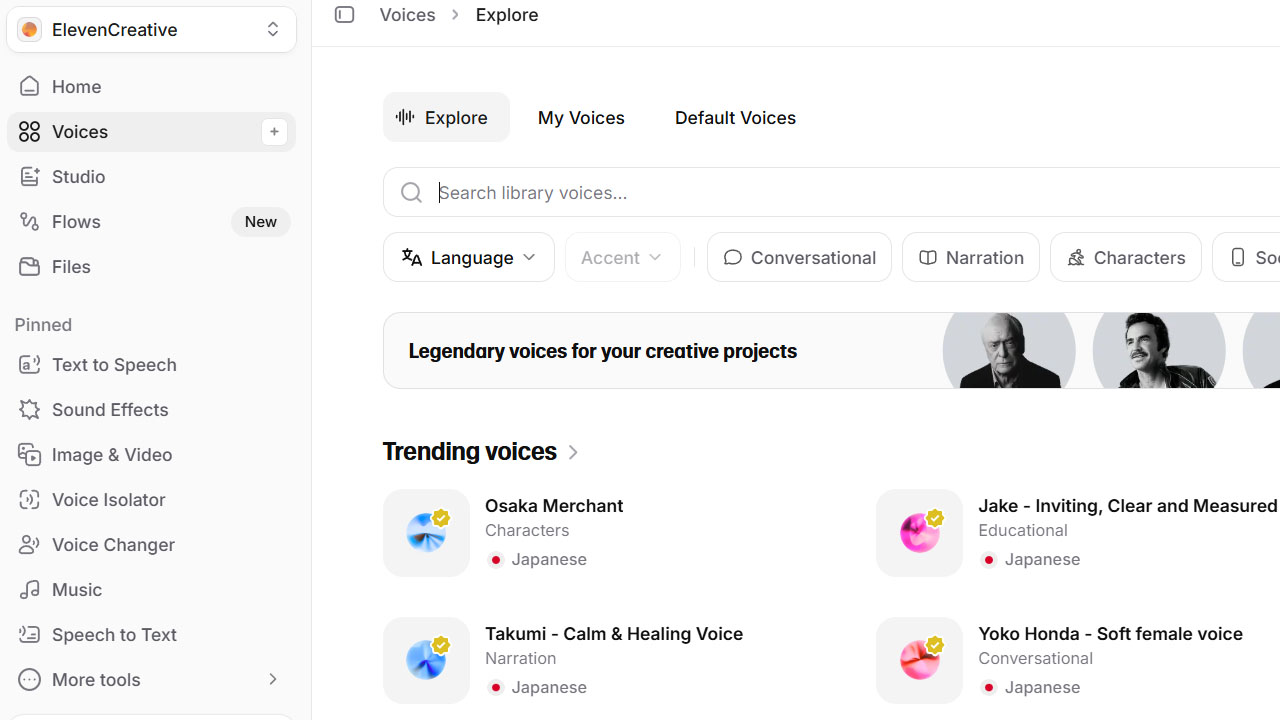
完全勝利や! と、500/1dayくらいのえらい勢いでシェア数が増えますが、収益はそんなに増えません。これは有料ユーザーの使用のみが収益配分に還元されるためです。
まあ、悪い気はしませんなあ・・・ぎょうさんつこてや。
Elvenlabsのまとめ
- Elvenlabsの音声の生成はほぼ商用レベル
- 無料版あり
- V3で日本語と漢字読み上げ精度が改善
- Professionalクローンの音声はほぼ本人
- 収益化にはCreator以上が必須
個人的にいまはV3がPofissionalクローンの声に対応するの待ちです。ロケでミスった音声のアフレコ、海外版作成はもう余裕です。