
OpenAIがSoraの終了を宣言しました。理由はリソースの不足です。コストは掛かるが、金は生まれない。
これはコード、チャットの専門サービスへの転換でしょう。たしかに画像生成や動画生成はリソースのブラックホールです。電気とGPUの処理能力をがぶがぶ食らう。
ということで、これはSoraが存命だったことのはなしですが、やはり、コンテクストは最重要ワードです。
AI動画の時代到来 OpenAIのSora 2フリー化
2025年12月までOpenAIのSora 2で15秒の動画をプロンプトで一日15本まで生成できました。SNSライクなショート動画の量産が恐ろしく捗る。
結局、招待コードを入手できなかったぼくはこのフリー化に満を持して、AI動画をじっくり触りました。
作例です。
イギリスの港町でフィッシュアンドチップスを食べながら歩く家族、1970年代風です。
左上の看板の文字が変ですが、その他はほぼナチュラルでスムーズです。指が6本になる、同じ人物が右に左に存在する、ような画像生成の初期の持病は出ません。
「ん、建物の傾きが変だぞ?」というのは初見ではほぼ分かりません。え、一発で分かった? それは慧眼だ。作ったぼくは三回目で気づきました。
とにかく90点の短尺の『スムーズ』な動画は普通に出来上がります。
もちろん、Sora 2用の英文プロンプトの出力はChatGPTのお仕事です。やはり、日本語プロンプトより英語プロンプトの方が『スムーズ』です。まあ、この解決も時間の問題ですが。
とにかくこのクオリティの『スムーズ』な動画が数分で出力されます。零細の動画クリエイターや編集マンには脅威、一般ユーザーには天恵です。
ところで、折よくAdobeのWeb版で3回の生成がキャンペーンで無料でした。早速、ぼくはPremiereのアカウントでFireflyからNano Banana Pro とVeo 3.1を試しました。
結果は上々です。むしろ、GoogleはOpenAIを抑えて、AIモデルの覇権を取りかねません。Gemini 3系の仕上がりは先代2.5とは別物です。
ITの歴史では最後発のChromeが最終的にブラウザの覇権を握りました。Geminiもおそらくそうなります。
さらにはあのディズニーがOpenAIと提携しました。ミッキーやアイアンマンのショートの大量発生が今から目に浮かびます。
しかし、まだまだOpenAIのSora 2やGoogle のVeo 3.1などの生成モデル、AI動画は万能ではありません。
そもそも何でAI動画はこんなに『スムーズ』でしょうか?
AI動画の長所と短所
ナチュラル、スムーズ、ぬるぬる
これらはゲームやアニメでは上位の賞賛です。ぼくのような低枚数紙芝居、作画崩壊、かくかくポリゴンを一頻りに通った世代にはなおさらです。
『劇場版吸血鬼ハンターDの手書きのぬるぬる作画はもうアートだな』とか『いや、OVAのゲッター1変形が神作画だ』とかなんとかが分かりますかね?
しかし、このぬるぬる作画、スムーズ動画、とくにシームレスはAIの生成動画では普通です。逆にかくかくの低FPSの動画の方がイレギュラーです。
さらには画面の変換、大胆なシーン変更、カット割りが非常に苦手です。
なぜか? それはAIモデルの学習方法に寄ります。
生成AIの動画がスムーズになる理由
最近の自動生成系のAIモデルはスケーリングで成長します。
- 大量のデータを
- 大量のGPUで
- 大量に処理させる
例えば、ごみ処理の分別ロボにAIを使うとします。このとき、
- そのごみ処理現場での特定のパターンや条件を限定的に学習させる
- より広範なパターンや条件を大量に学習させる
『専門特化か詰め込みか』ですが、最近の研究では後者の2がより成長するという結論です。富野監督の『良いアニメを作るならたくさんの映画や音楽を鑑賞しろ!』という名言に通じます。
さらには元ハンマー投げの室伏広治がハンマーを投げず、筋トレをせず、漁の網を投げるとか、指を鍛えるとかで飛距離のレベルアップを試みたという逸話にも繋がります。
つまり、ある分野の成長のブレイクスルーは具体的な狭義のパターンの中でなく、不特定の周辺的なサブパターンの中から生まれるというのがAI成長の潮流です。
ゆえに大手テック系企業は大量のGPUを買って、大量のデータを食わせて、モデルの成長をうながします。
最近のデータセンターの乱立はこのためです。そして、今は動画ですが、次は動作です。
テキスト、静止画、動画、3D動作、世界シミュレーションではGPUの量が指数関数的に増えます。結果、Nvidiaのブラックウェルが瞬間蒸発的に完売御礼となります。
で、おそらくこの流れは動作生成モデル搭載のロボットが普及するまで続きます。
動画のスケーリング
AIモデルは詰め込み教育然としたスケーリングで成長します。GPUは胃袋で、データは食事です。では、その食事の出所、食材の畑はどこでしょう?
ヒントです。
- ネット上のテキストの最大のスケールは検索
- ネット上の位置情報の最大のスケールはマップ
- ネット上の動画の最大のスケールはYoutube
はい、すべてがGoogle=Alphabetの管轄下にあります。
OpenAIなどのAI企業はモデルのスケーリングにこれらを使わざるを得ません。
スケーリングの要は量です。ネット上のいろいろな最大量はどこにあるか? Google検索、Googleマップ、Youtubeです。
今のところ、アクション、動作のスケールの覇者は不明ですが、動作や物理は動画から抽出されます。つまり、Youtubeのバックヤードのデータはアクションの分母になります。
となると、動作のスケールもGoogleの手に落ちます。AIモデルのスケール論は完全に同社に追い風です。
極論、Googleが本気を出せば、他のAI企業に「うちのデータでスケーリングするな」と言えます。
実際問題、OepnAIがSora 1を発表したとき、学習元を最後まで明かさず、「知らん」とはぐらかしたという逸話があります。
しかし、ネット上の最大のスケールはGoogleの配下にあります。YouTubeの大量の動画を学習するのがスケーリング論的には絶対的正解です。
「知らん(言えない)」
AIは読めませんが、ハイテク業界人は読めます。これが後述の『コンテクスト』です。
編集された動画は少数派
ところで、ぼくらの目に触れる動画、TV、ネット、SNSのコンテンツは自然なものではありません。
- 編集
- おすすめ、レコメンド、パーソナライズ
- 宣伝、PR、キャンペーン
テレビ番組はきっちり編集された長尺の動画コンテンツです。地方のローカル局の謎の安っぽいCMも撮って出しの生素材ではない。
YouTubeやSNSではおすすめ動画がアルゴリズムで流されます。厳選と抽出済み。サイトのトップから素体の無加工の動画を探すのは簡単ではない。
他方、垂れ流し配信、定点ライブカメラはコンテンツより生の素材、『フッテージ』に近付きます。ドライブレコーダーや監視カメラなどはまさに生の生です。
ぼくらが日常的に見るor見せられる動画はオンラインの動画の中の氷山の一角です。その裏には1000倍以上の無加工、無編集、無作為の動画が大量に存在します。
本当でしょうか? あなたのオンラインストレージやメールの下書きにスマホで撮った猫の動画や近所の風景、ラーメンの画像がありませんか? で、それは編集済みですか?
動画の大半はフッテージ
ショーウィンドのきらびやかな商品がバックヤードに大量に雑然とあるのと同じく消費コンテンツの裏には大量のフッテージがあります。
AIモデルはこれを食って成長します。正式にやるならば、お金で使用権(APIなど)を買います。非公式にやるならば、Googleの好意に甘えて、こっそり盗み食いします。
とにかく選り好みをせず、片っ端から食い漁るのがスケーリングです。選り好みをするのは推論モデルですが、こちらは主流ではありません。
で、このときのデータの大半は生のフッテージです。雑多な日常の記録、ドライブレコーダーみたいな長時間の映像、定点の無加工の風景などなど。
カット割りされた映画
編集された番組
バズるショート
こういうものは満腹の胃の中のゴマ粒みたいなものです。動画データのなかではイレギュラーの少数派だ。
トマトのほとんどは水分ですが、人間は少量のリコピンだけを取れないので、それをまるまる食べます。
AIモデルもデータの中から必要な要素だけを取れません。片っ端から食べまくって、微小な栄養を混ぜ合わせて、ブレイクスルーを果たします。
そもそも『ブレイクスルーに必要な要素』というのが明確ではありません。それが事前には分からない。
また、必要か不要かを人間が判断すると、時間と費用が掛かります。そして、それは旧来のプログラムと変わりません。AIの分野ではない。
シームレスでぬるぬるの理由
上記のようにぼくらが見るコンテンツは動画データの海の中では少数派で、ぼくらが見ないものが多数派です。分子と分母だ。
そして、分母、多数派、素の生の無編集の未加工の動画データ、フッテージはシームレスでぬるぬるです。それは現実世界のコピー、日常の切り取りです。
当然のごとく現実にはカット割りなどはありません。左から右に目線を流しましょう。はい、完全なるシームレスです。
それを食うAIがそれを吐き出すのは簡単です。一発撮り、定点、シームレスは得意中の得意です。AIの中の『動画』とやらの概念はそれですから。
さらにそれを生成する最重要パーツのGPU、古い言葉で『グラボ』や『ビデオカード』はゲームの3D描写のためのものです。
『リアルな仮想空間をリッチに動かす』
このためにグラボの性能は上がり続けました。SKYRIMやGTAみたいなオープンワールドのシームレスなゲームはGPUなしで成立しません。

で、シームレスなオープンワールドには時空と物理の整合性があります。
ゲーム内の昼は急に夜になりませんし、キャラは高いところから落ちるとふつうに死にますし、ファストトラベルでは時間が経過します。
これを描画するための装置がシームレスな動画を得意とするのは当然です。GPUは映画みたいなカット割り映像製造マシーンでないので。
また、時空と物理の整合性を保てるならば、現実世界を生成できます。これが『世界モデル』です。
『実際の工場や現場の設計図や測量データを入れて、効率的な人員の配置やメカの導線を確保するためのシミュレーション案をいくつか出す』
このような使い方が研究中です。
カットは時空の破綻
動画は動作に繋がり、動作は物理に至ります。一つのシームレスな動画の中の人物や物体や環境の動きはスムーズでナチュラルです。
他方、カット割りは時空の超越ないし破綻です。
- 人物
- ナイフ
- 死体
- 血
これらの4つの単語は『なにがしかの凶行』を暗示します。人間は過去の体験や知識からそれを理解できます。

しかし、AIにはこれらの個々のカットや物体は個別の独立の時空の事象です。重みつけやスタイルの指定、関連性がなければ、それぞれが個別に平等に配置されます。
また、このような特定の状況は現実のフッテージには多くありません。そんな犯行現場のリアル記録がネット上にいっぱいあるのもあれですが・・・
かりにこのようなシーンを動画生成するならば、『犯行現場のような』みたいな指示を入れます。
AIはこの指示を受ければ、『犯行現場』の場面を探しに行きます。で、さっきの4つのテキストを凶行風に並べられる。
ちなみに上のカットは4つのワードからの生成です。『犯行現場風の』や『小説の挿絵風の』の補完がすでにここまで自動で入ります。
さらに『シネマノワール風の』や『ギャング映画風の』のようなスタイル、抽象的な共通記号、コンテクストの指定をすれば、そのジャンルの独特の演出や映像の雰囲気を付与できます。
無指定の単純なカットはAIには時空の超越と破綻です。ぼくらの感性、映像常識の中ではこれはナチュラルですが、AIの思想ではイレギュラー、バグです。
一つのシーンには形、動き、光源、影の位置みたいな情報があります。これを連続的につぎの段階へ動かす=現実世界の模倣です。
これの学習データは大量にあります。どこに? YouTubeなどに。フッテージはシームレスで連続的です。ある種、人間世界の模倣、現実世界の切り出しだ。
そして、AIは物理整合性を重視します。なぜか? 学習の分母の動画のフッテージのベース=現実世界がそうだから。ぼくらの周囲の空間にカットやVFXは存在しません。
また、ぬるぬる=フレーム補助ですが、これもAIの得意分野です。30FPSを60FPSにするのは難しくない。一つ前のコマと一つ後のコマを参照にして、連続的な中間を作るだけです。
他方、カットは時空の連続性の断絶です。文字通りのカット。完全なリセットと再生成では一つ前の時空のキャラクターや背景が別物になってしまいかねません。
しかし、一つ目の時空の要素を引き継ぐと、動作や物理をも継続してしまいます。二つ目の時空が一つ目の法則に引きずられる。
個人的な感覚ではこの物理優先傾向はSORAにより強く出ます。VEOの挙動はややビジュアルを優先する風に思える。これを踏まえて、現状ではぼくはSORAに軍配を上げます。
解決策は一つ目のキャラクターにタグやメタデータを付けて、それだけを部分的に継続するみたいな方法です。キャラだけを並行世界に転送する、みたいに。
この点、『深夜のローカルCM風の』みたいな抽象的なスタイル指示を出すと、そのようなカットやスタイルを優先して、物理的整合性の順位を下げます。
つまり、『生成する動画のシーンの元ネタのコンテクストをプロンプトに含められるか?』が重要です。
これをできないと、固定テキストや具体的な指示、『こっちから明るく撮って、足元をアップして、俯瞰で撮って』みたいな煩雑さの谷に落ち込みます。
あと、権利の問題から特定のタイトルや作品名・・・『ゴッドファーザーみたいな』より『ハリウッドのギャング映画風の』のような抽象的な共通の記号の方が倫理的です。
カメと忍者
カメと忍者
もちろん、これはTMNT、ティーンエイジ・ミュータント・ニンジャ・タートルズの暗示です。人間界ではこの二つのワードはこの人気シリーズを差します。
しかし、AIにはカメと忍者はカメと忍者です。補足で『それはタートルズのことですか?』と来ます。最初のレイヤーに『タートルズ』はない。
🐶🚀
これはややマイナーになりますが、暗号資産界隈では一瞬で通じます。「inu系のコインが爆上げ!」です。DogecoinかShiba Inuかは不明ですが。
このように本質的に無関係なテキストやキーワード、具体的な記号から抽象的なコンテクスト、文脈を理解するのは依然として人間のものです。AIはまだここまで奪いません。
逆にタートルズを因数分解して、カメと忍者の記号に具体化するのはAIの十八番です。
仮にタートルズが存在しないと、カメと忍者はAIの中ではほぼ繋がりません。その画像の生成結果はカメと忍者になります。
ちなみにChatGPTの『カメと忍者のイラスト』の生成結果です。

“カメと忍者”です。”カメ,忍者”の方が適切だったか? とにかく、タートルズは出ません。本来のカメと忍者はこうなります。で、間違いではない。
もっとも、タートルズはメジャーですから、そのフッテージは生成の母数には十分です。『カメの忍者』あたりはもう権利的にまずいものが出ます、たぶん。
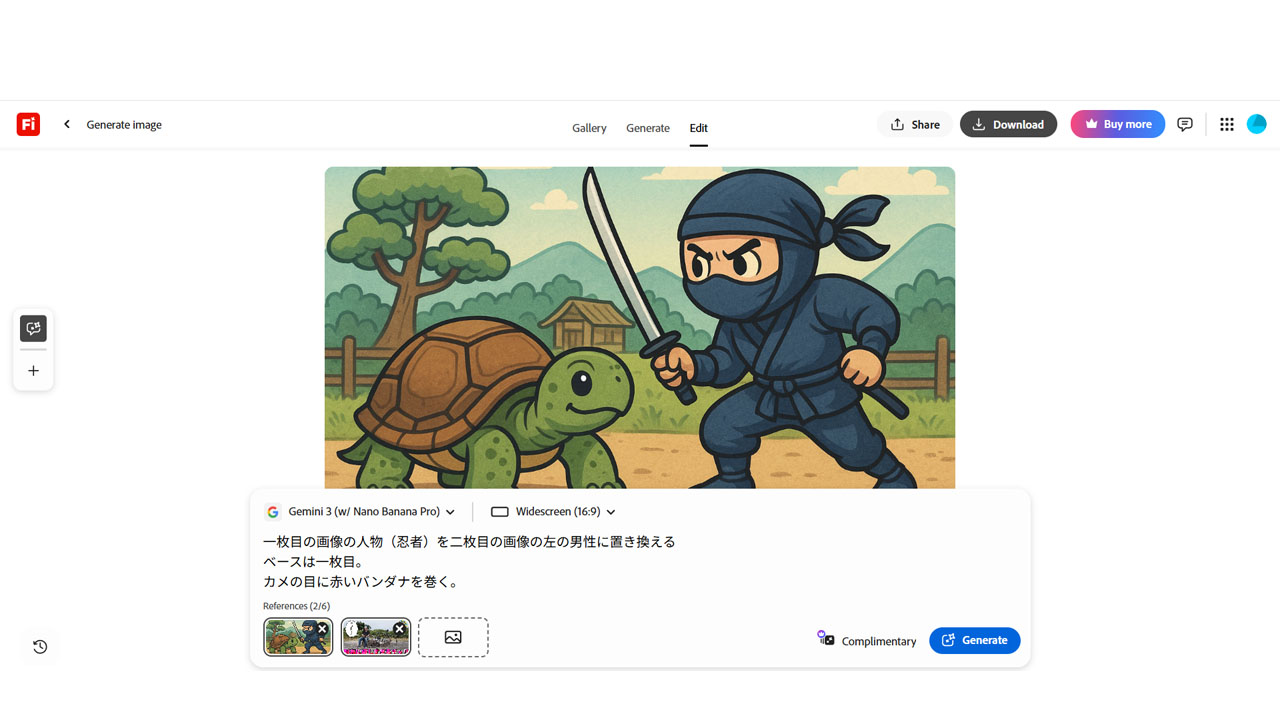
ついでにこの記事の冒頭のNano Bananaの二枚合成を披露しましょう。
プロンプト
一枚目の画像の人物(忍者)を二枚目の画像の左の男性に置き換える
ベースは一枚目。
カメの目に赤いバンダナを巻く。

うーん、巷のイラストレーターの悲鳴が聞こえる・・・で、左のカメの名前はたぶんラファエロです。
ただし、これもAIの判断では『赤いバンダナを目に巻いたカメ』です。TMNTではない。
そして、この画像は具体性のかたまりですから、これを参照にして動画を作ると、このカトゥーン風を保ちつつ、ミニアニメを作れます。
最近のモデルは旧来のコンピューターと違って、画像データを色の羅列と見ず、左のものを『カメ』、右のものを『人』と認識できます。あと、ここは顔、ここは足、ここは布地とかも。
で、カメは爬虫類、雑食、鈍重な生き物、長寿、驚くと甲羅に引っ込む、うんぬんかんぬん・・・みたいなことを類推できます。初歩的な抽象化がもう可能です。
で、このような参照画像を使わないなら、カメに赤いバンダナを巻いて、人間型にして、武器を持たして、忍者風にして、アニメ調にしてみたいな狭義の記号を入れなければなりません。
また、抽象化できる人、コンテクストで補完できる人は『タートルズみたいな』や『カトゥーン風』や『昔のごりごりのアメリカンな初期アニメのように』などの大枠を決められます。
もちろん、この場合、元ネタのスタイルや世界観を知らないと、適切なプロンプトを書けません。1987年版は2018版と全く別物ですし。
コンテクストとストーリーテリング
このようにコンテクストとストーリーテリングは現在のAI動画の活用には不可欠です。
文章作成、実用的なレポートや記事を作るなら、具体的な知識、キーワードの連続でおおむね生成できます。ブロック間、章別の破綻はそう起こりません。長編小説はやや不安定ですが。
しかし、動画ではカットごとの違和感が発生します。イメージ通りのシーンを具体的な狭義のキーワードだけで作るのは大変です。
これを補うのがコンテクストとストーリーテリングです。これには横断能力が必須です。
- 文脈 A(カルチャー)
- 文脈 B(テクノロジー)
- 文脈 C(ネット)
- 文脈 D(金融)
- 文脈 E(地政学)
- 文脈 F(宗教)
「あれとあれは別ジャンルだが、この部分で共通する」
「それとこれは似る」
「このジャンルのこの逸話はこのカテゴリのこの層に受ける」
こういうのを察知できる人はAI動画にはすごくフレンドリーです。ことさらに雑学好き、考察マニアは絶対的に有利ですし、めちゃくちゃ遊べます。
専門特化型、深い狭い知識は貴重なデータ元にはなりますが、動画作成、コンテンツのクオリティにはそこまで貢献しません。
そして、すでに多方面でAIが専門職レベルに到達します。最近のモデルは医者の試験や弁護士の資格、金融の難関に合格し、初代ポケモン赤緑をクリアできるそうな。
ChatGPTのシンプルなIQがおおよそ約145〜160以上です。人間の99.9%よりAIの方が優秀です。計算問題は余裕、大学試験は朝飯前です。
が、情緒、感性、抽象性は並みで、最新ニュース、ゴシップ、ミームなどの知識はそこらへんのミーハーな人々以下です。
とくにオープンな汎用公開モデルはそう頻繁にアップデートされません。バージョンアップは一年に一回くらいです。時事ネタの答えがときどき古くなる。
しかし、知識、記憶の答えはほぼ満点です。で、世の試験の大半はマークシート、記憶の有無と正誤です。人間はコンピューターにテストでは勝てない。
幼児と小学生
静止画の生成にはタグ、キーワードが効きます。
赤
リンゴ
2つ
シンプルな絵はこの幼児的な言葉の羅列でそこそこ成立します。しかし、動画はこのシンプルなタグではうまく行きません。
2つの赤いリンゴ? 横に並べる? 手前と奥にする? どうする?
『てにをは』と動詞の補助がなければ、動画が仕上がりません。多分に上記のタグだけの生成内容は2つの赤いリンゴにゆっくりズームインするような動画もどきになります。
これは静止画でこそありませんが、動画、消費コンテンツにはなりません。それをAIで作る意味がない。
動画生成には小学生以上の指示が必要です。
「赤いリンゴを2つに切る」
動画AIはこの指示を待ちます。それを得られないと、補完しすぎておかしい結果を出すか、補完しなさすぎて曖昧な結果を出すというミスをやらかします。
が、AIの構造ではこれはミスでなく、大正解です。2つの赤いリンゴのじわじわズーム、ぜんぜん間違いではない。タグとシーンの時空の物理的整合性は完全です。
ミメーシスとメタファー
ミメーシスは模倣で、メタファーは比喩です。前者はAIの得意分野です。
動画のスケーリングのベースにはYouTubeなどのデータがあります。その99.999%くらいは無編集、無加工、無厳選のフッテージ、現実世界のコピー、動作と物理のショーウインドウです。
で、これの模倣はAIには比較的に簡単です。脳の奥と腹の中はこれでぱんぱんですから。
他方、メタファーは比喩、たとえ、推測と抽象、個別の事象の関連付けです。このスケールは単純に容量不足です。
メタファーのスケールの畑があるか? Reddit? 小説投稿サイト? Gmail? SNS? でも、それを静止画と動画にどう繋ぐ? ブリッジ的な機能はぱっと思い浮かびません。
ちなみにGoogleはSNSでこけました。Google+というのがあったなあ・・・
METAなどは一定の条件を備えますが、ここのAIモデルの評判がイマイチです。
結局のところ、現状では人間がこのスケールを握ります。まあ、将来的にはコンテクスト、ストーリーテリング、メタファーも吸収されますが。
しかし、工場や自動運転AIモデルの方が実務的に有用ですから、メタファーよりアクションの模倣と生成の実用化が優先でしょう。ここは意外と末永く人間側に残る…ことが個人的な希望です。
コンテクスト、ストーリーテリング、ミメーシス、メタファーさえがAIに渡ってしまうと、人間の創作活動がほぼ消滅します。
じゃあ、我々は何をします? 自動生成コンテンツを楽しんで、ロボに仕事を任せて、体を鍛えて、AIと地球に感謝する? うーん、悪くない。
AI動画生成のまとめ
- OpenAIのSora 2がフリーに
- GeminiのNano BananaとVEOも良
- AI動画モデルはシームレスに強く、カットに弱い
- オンラインの動画データ=人間世界の見本市=動作と物理の源泉
- Googleが本気を出すと勝つ
- 時空の連続性で繋げないなら、コンテクストで補完する
ぼくの個人的な感覚では
1シーンに収める
カットの繋ぎに妥協する
音でごまかす
そういう崩れを味に(低予算トレイラー風にとか)にする
とかがコツです。
『ハイクオリティなシーンをマルチカットで繋いで、映画みたいな作品を作る』は現状のAI生成モデルには不可です。クオリティかカット、どちらかの犠牲が必要です。